
作者:钱天培
“病史:肿胀、疼痛,已获取左踝关节三视图。”
“病情:矿化正常,未发现骨折或骨性病变 ... 软组织正常。”
“结论:左踝关节正常。”
观察X光照片、记录病情、翻看患者病史、给出诊断结果——这是一位放射科医生的日常工作。
长期以来,放射科医生的这项工作既繁琐、又容易出错。幸运的是,斯坦福大学的一项最新研究成果表明,AI技术可以自动生成的放射科报告:在一个盲选实验中,一位放射科医生判断67%自动生成的诊断报告达到、甚至超越了专业放射科医生书写报告的水准。
医生只需在观察X关照片后描述影像信息,简述患者病史,人工智能模型便会自动生成高准确性的诊断总结报告。
近日,由斯坦福Curtis Langlotz和Chris Manning教授指导的团队发表了他们将自然语言处理技术应用于医疗诊断的最新成果。在这项研究中,他们运用自然语言处理模型阅读医生对X光照片的描述,结合患者病史,自动生成精准、流畅的诊断结果。
“我们的深度学习模型能够自动给出诊断结果,生成的总结报告与人类医生的诊断高度吻合。” 该研究的第一作者张宇浩告诉文摘。
诊断报告的自动生成
该研究将诊断报告的自动生成看作了一个“文本概括”问题。长篇的病情记录被视作需要概括的文本,而这一概括过程又需要结合患者的病史信息。
为了解决这一问题,该研究使用了一个基于长短神经网络(LSTM)的seq2seq模型作为主结构。
首先,病情记录被一个LSTM编码器转换成向量表示。同时,患者的病史信息也被另一个LSTM网络编码。之后,基于这些病情记录和病史信息的编码信息,一个LSTM解码器逐字生成最终的诊断报告。
这一模型同时具备“复制-黏贴”功能。在解码器生成诊断报告的过程中,可以选择生成词库中的合适词汇,或者直接从病情记录中“复制-黏贴”相关文字。
模型的完整结构如下图所示。
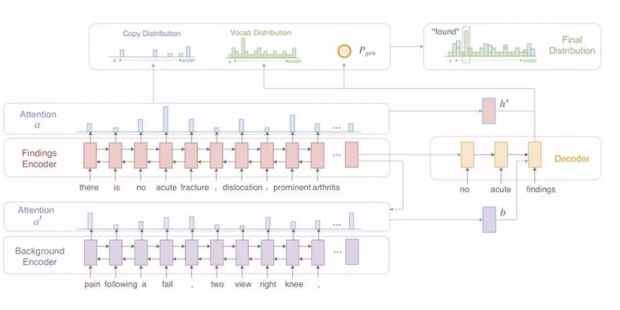
考虑到医疗诊断报告的文本区别于普通文本,在词汇量、词汇用法语义都存在特殊性,该研究在450万放射科报道上预训练了一组全新的GLoVe词向量。结果显示,这一做法能够显著提升诊断报告的质量。
该研究主要使用的数据为87,127份斯坦福医院的X光诊断报告,这些报告囊括了12种不同的身体部位,包括胸部,腹部和四肢等。
诊断报告质量显著提升
为量化生成报告的质量,这份研究使用了ROUGE分数作为评估指标。该指标衡量了生成文本和真实文本的重合度。
研究者们将新模型与S&J-LSA、LexRank、Pointer-Generator等基准模型作了对比。结果显示,研究提出的新模型显著优于其他模型算法。比对模型的详细信息参见原论文。
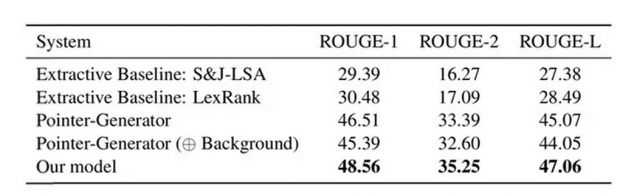
同时,研究者也请来了一位资深放射科医生来人工评估报告质量。在一个盲选实验中,该医生认为67%自动生成的诊断报告达到、甚至超越了专业放射科医生书写报告的水准。
研究者们也探究了该模型的应用广泛程度。
在深度学习模型训练中,一个经常困扰研究者的问题是,在已有数据集上训练好的模型在实际应用场景中会因为数据分布的不同而“大失水准”。
那么,这个模型能否被应用到其他医院的诊断报告上?由于不同机构的放射科医生往往经过不同的训练,并且有不同的写作习惯,将这一模型迁移到其他医院的诊断流程中是一个潜在的有挑战的问题。
为此,研究者们在斯坦福医院数据集上训练完模型后,直接将该模型在2,691份印第安纳大学胸部X光诊断数据集上测试。令人欣喜的是,这一模型同样有不错的表现。

另外,这个模型是否也能够为训练中没有见过的“身体部位”作出诊断呢?在实际应用中,一些在诊疗过程中罕见的身体部位可能在训练过程中完全缺失。
为了研究这一问题,研究者将所有数据按照身体部位分类,并分别抽出每个部位对应的数据,在剩余数据上训练模型。结果显示,“胸部”和“腹部”的诊断严重依赖相关训练数据集,而“膝关节”的诊断则显现出较小的数据依赖性。作者猜测,这是因为训练数据集中存在和“膝关节”相似的身体部位,如“踝关节”、“肘关节”等。

未来计划
通过对机器生成报告的逐条分析,研究者发现模型仍存在一些问题。该模型偶尔会遗漏重要结论,比如必要的后续诊断建议。同时,模型生成的报告仍存在一些的语法错误。
研究者们也正在考虑如何将这一成果于实际诊断有效结合,做到确保诊断质量的同时有效精简放射医生的工作量。
“希望我们的成果能够启发其他研究者们,进行更多医疗诊断报告自动生成的探索。”作者张宇浩告诉文摘。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}