阅读:0
听报道

编译:、茶西、jin、蒋宝尚
这年头,你不会点儿统计学,你都不好意思出去闯荡江湖。
α值、P值、假设检验这都是些啥?一个小案例带你了解的透透的。
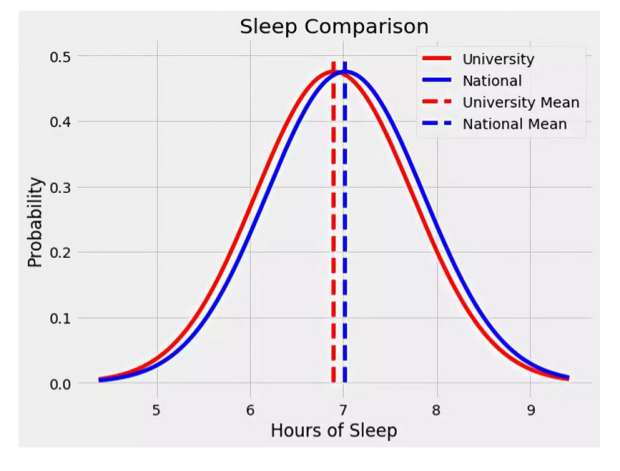
假设你是一所大学的院长,你收到一份相关报告显示你的学生每晚平均睡眠时间为6.80小时,而全国大学学生的平均睡眠时间为7.02小时。
此时,学生会主席出于对学生健康的考虑,宣称这项研究的结果证明了减少家庭作业是必须的。另一方面,校长认为这项研究是无稽之谈:“在过去,我们能够每晚睡4个小时就很好了。”
但是,你必须决定这是否应该引起重视,这个问题就可以使用统计学的知识来解决。
我们经常听到统计显著性,但其实并没有真正理解其含义。如果有人声称数据可以证明他们的观点,我们往往会不假思索的接受,因为我们默认统计分析员经过了一系列复杂的数据分析后得出了不可置疑的结果。
事实上,统计显著性并不复杂,也不需要经过多年的学习才能掌握,它是非常直截了当的思路,每个人都可以并且应该理解。与大多数技术概念一样,统计显著性建立在一些简单的概念基础上:假设检验,正态分布和p值。本文将阐述这些概念,并逐步解决上述例子中的问题。
假设检验
我们要讨论的第一个概念是假设检验(hypothesis testing),这是一种使用数据评估理论的方法。“假设”是指研究人员在进行研究之前对情况的初始信念。这个初始信念被称为备择假设(alternative hypothesis),而相反的被称为零假设(null hypothesis)(也叫原假设)。具体到例子中就是:
备择假设:本校学生的平均睡眠时间低于大学生的全国平均水平。
零假设:本校学生的平均睡眠事件不低于大学生的全国平均水平。
需要注意的是,我们必须要谨慎用语:因为我们要检验一个非常具体的效应,所以需要在假设中规范用语,才能在事后说明我们确实验证了假设而非其他。
假设检验是统计学的基础之一,用于评估大多数研究的结果。适用范围覆盖了从评估药物有效性的医学试验到评估运动计划的观察性研究等各种研究。
这些研究的共同点是,他们关注两组之间或样本与整体之间进行比较。例如,在医学中,我们可以比较服用两种不同药物的群体之间得以恢复的平均时间。而在我们的问题中,需要比较本校学生和本国所有大学生之间的睡眠时间。
有了假设检验,我们就可以使用证据来决定是零假设还是备择假设。假设检验有很多种,这里我们将使用z检验。但是,在我们开始测试数据之前,还需要解释另外两个更重要的概念。
正态分布
第二个概念是正态分布(normal distribution),也称为高斯(Gaussian)或钟形曲线(Bell curve)。正态分布是利用平均数和标准差来定义的数据分布形态,其中平均数用希腊字母μ (mu)表示,决定了分布的位置,标准差用σ (sigma)表示,决定了分布的幅度。
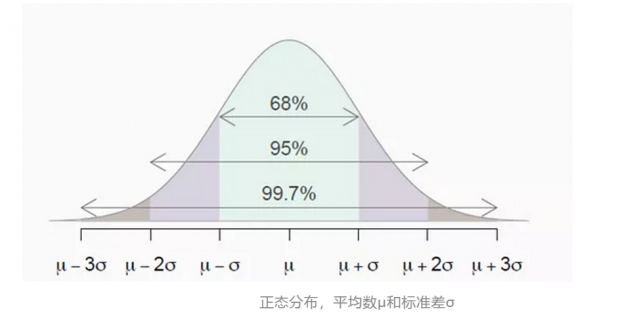
正态分布的应用原理是根据标准差来评估观测值。我们可以根据与平均值的标准偏差数来确定观测值的异常程度。正态分布具有以下属性:
68%的数据与平均值相差±1标准差
95%的数据与平均值相差±2标准差
99.7%的数据与平均值相差±3个标准差
如果我们统计量呈正态分布,我们就可以根据与均值的标准偏差来表征任意观测点。例如,美国女性的平均身高是65英寸(5英尺5英寸),标准差为4英寸。如果我们新认识了73英寸高的女性,那么我们可以说她比平均身高高出两个标准差,属于2.5%的最高身高的女性(其中有2.5%的女性要矮于μ-2σ(57英寸),2.5%要高于μ+2σ)。
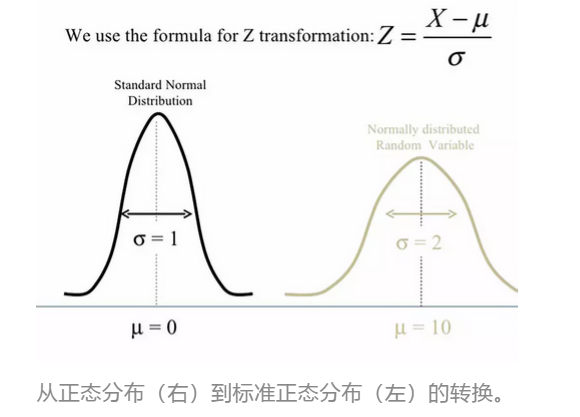
在统计学中,我们不直接说我们的数据与平均值相差两个标准差,而是用z分数来评估,z分数表示观测值与平均值之间的标准差的数量。我们需要利用公式将数据转化为z分数:观测值减去平均值,除以标准差(见下图)。在身高的示例中,我们可以得到朋友的身高的z分数为2。如果我们对所有观测值进行z分数转化,就会得到一个新的分布——标准正态分布,其平均值为0,标准差为1,如图所示:
每次我们进行假设检验时,都需要假定一个检验统计量,在我们的例子中是学生的平均睡眠时间。在z检验中,我们通常假定统计检验量的分布近似正态分布。因为,根据中心极限定理(central limit theorem),从总体数据中获得越多的数据值,这些数据值的平均数则越接近于正态分布。
然而,这始终是一个估计,因为真实世界的数据永远不会完全遵循正态分布。假设正态分布能够让我们确定在研究中观察到的结果有多少意义,我们可以观察z分数,z分数越高或越低,结果越不可能是偶然发生,也就越具有意义。为了量化结果的意义,我们需要使用另一个概念。
P值和α是个啥!
最后的核心概念是p值。p值是当零假设为真时所得观察到的结果,或是更为极端的结果出现的概念。这有点令人费解,所以让我们来看一个例子。
假设我们要比较美国佛罗里达州和华盛顿州人民的平均智商。我们的零假设是华盛顿的平均智商不高于佛罗里达的平均智商。
通过研究发现,华盛顿州的人民智商比佛罗里达州人民智商高2.2,其p值为0.346(大于显著性水平)。这意味着,零假设“华盛顿的平均智商不高于佛罗里达的平均智商”为真,也就是说,华盛顿的智商实际上并没有更高,但是由于随机噪声的影响,仍然有34.6%的概率我们会测量到其智商分数会高出2.2分。之后随着p值降低,结果就更有意义,因为噪声的影响也会越来越小。
这个结果是否具有统计意义取决于我们在实验开始之前设定的显著性水平——alpha。如果观察到的p值小于α,则结果在统计学上具有意义。我们需要在实验前选择alpha,因为如果等到实验结束再选择的话,我们就可以根据我们的结果选一个数字来证明结果是显著的,却不管数据真正显示了什么,这是一种数据欺骗的行为。

α的选择取决于实际情况和研究领域,但最常用的值是0.05,相当于有5%的可能性结果是随机发生的。在我的实验中,从0.1到0.001之间都是比较常用的数值。也有较为极端的例子,发现希格斯玻色子(Higgs Boson particle)的物理学家使用的p值为0.0000003,即350万分之一的概率结果由偶然因素造成。(现代统计学之父R.A.Fischer不知为什么,随便选择了0.05为p值,很多统计学家极其不想承认这一点,并且这个值现在让许多统计学家非常困扰与担忧)!
要从z值得到p值,我们需要使用像R这样的表格统计软件,它们会在结果中将显示z值低于计算值的概率。例如,z值为2,p值为0.977,这意味着我们随机观察到z值高于2的概率只有2.3%。
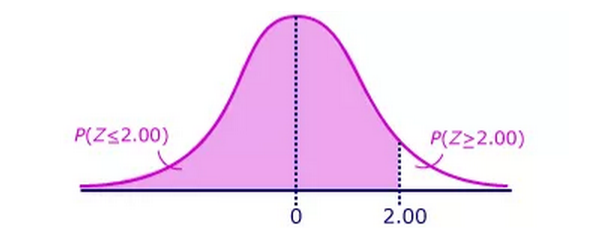
正态分布下z值低于2的概率为97.7%
总结应用
我们做个总结,截止到目前提到了三个概念
1.假设检验:用来检验理论的方法。
2.正态分布:假设检验中对数据分布形态的近似表示。
3.P值:当零假设为真时观察到的或是出现更为极端结果的概率。
现在让我们把这些概念带入到我们的例子中:
根据国家睡眠基金会(the National Sleep Foundation)的数据,全国学生平均每晚睡眠时间为7.02小时。
针对本校202名学生进行的一项调查发现,本校学生的平均每晚睡眠时间为6.90小时,标准差为0.84小时。
我们的备择假设是,本校学生的平均睡眠时间少于全国大学生的平均睡眠时间。
我们将选取0.05为α值,这意味着当p值低于0.05时,结果是显著的。
首先,我们需要把测量值转换成z分数,用测量值减去平均值(全国大学生平均睡眠时间),除以标准差与样本量平方根的商(如下图)。另外,随样本量的增加,标准差亦随之减少,这一点可以用标准差除以样本量的平方根来解释。

Z分数就是我们的检验统计量。一旦我们有了检验统计量,我们就可以使用像R这样的程序语言来计算p值。这里展示代码只是为了说明使用这些免费的分析工具来进行操作是多么的容易!(#号是表示备注,加粗字体是输出值)
# Calculate the results
z_score = (6.90 - 7.02) / (0.84 / sqrt(202))
p_value = pnorm(z_score)
# Print our results
sprintf('The p-value is %0:5f for a z-score of %0.5f.', p_value, z_score)
"The p-value is 0.02116 for a z-score of -2.03038."
因为p值为0.02116,所以我们可以拒绝零假设(统计学家喜欢说拒绝零假设,而不是接受备择假设。) 。也就是说,虽然我们的结果有2.12%的概率由随机噪声引起,但在显著性水平为0.05的情况下,本校学生平均睡眠时间比美国大学生平均睡眠时间少,这一假设在统计学上显著。因此,在这场辩论中,学生会主席的观点得到了支持。
但是,我们不能太过相信这一结果,而立即叫停所有的家庭作业。因为,如果我们选用0.01为临界值,则p值(0.02116)未达到显著。所以,如果有人想要证明相反的观点,可以简单地通过操纵p值来实现。因此,无论何时,当我们审查一项研究时,除了结论外,我们还应该考虑p值和样本大小。
本例中,因为202是个相对较小的样本数量,所以我们的研究结果不仅有统计意义,同时具有实际意义。需要说明的是,这是一项观察性研究,只有相关性,而不能得出因果关系。我们的结果表明了本校学生和平均睡眠不足是有之间的相关关系,但并不是意味着来我们学校会导致睡眠减少,这其中可能还存在其他因素影响睡眠,只有通过随机对照研究才能证明其因果关系。
与大多数技术概念一样,统计显著性并不那么复杂,只是许多小概念的集成体,最主要的麻烦来自于学习那些术语!但是一旦你掌握了这些小概念,并将其结合起来,就可以开始应用这些统计概念了。
你会发现,当掌握了统计学的基本知识后,你就能够以一种健康的怀疑态度来更好的审视一些研究和信息,你可以看到数据实际上表达了什么,而不是别人告诉你数据意味着什么。或许这就是对付狡猾的政客和公司的最佳策略——通过统计知识的普及与训练来提高公众的质疑能力。
相关报道:
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}