
编译:DonFJ
聊起机器学习的时候,人们总觉得它特别的神秘。我们知道AI算法能完成一些任务,但是不知道它具体是怎么做到的。
严格的来说,机器学习算法是人工智能AI的一个分支,但是我们其实也可以把它当成一种预测算法看待。
比如根据一个影迷在豆瓣上评分的数据,算法能预测出ta喜欢什么样的电影;根据一个求职者的履历,算法能预测它这次去面试被刷的几率;或者说(重点来了!)根据过去几年里万圣节服装的订单,算法能够预测今年的狂欢中人们是怎么装扮自己的。
万圣节的装扮预测好像是个不错的话题哈(没错,我们就是在蹭热度!)。为了实现这个小应用,我们找到了一个叫“textgenrnn”的算法,它的能力是模仿文本。
textgenrnn的作者叫Max Woolf,他开源的这个算法在开始的时候没有任何知识,就是一个白板。它可以根据你输入的任何的文字进行学习。所以我们首先拿到了一年内人们发送给的7182个万圣节服装订单,然后把这个订单的文字信息喂给textgenrnn,看看能发生什么有趣的事情。
textgenrnn的github链接:
的链接是:嗯,就是它自己,看名字就知道不是什么正经的服装厂哈哈
下面就是算法产生的一些结果:
算法很聪明,在没有人来教它的情况下,仅仅根据我们输入的订单信息就学到了上面图片里面的单词和词组。
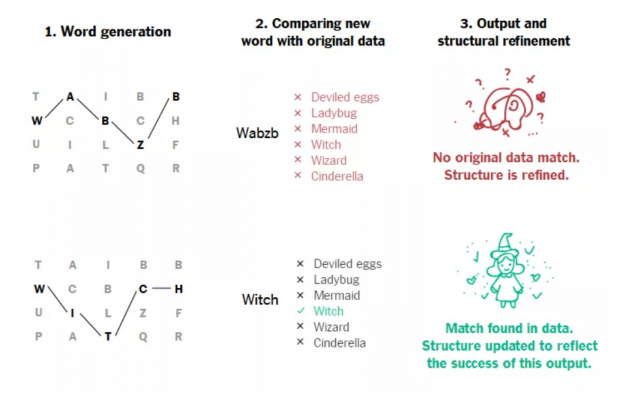
这个算法这这样工作的,首先它要预测每个订单里的衣服的名称,名称就是英文单词啦。
然后它会自己检查一下预测的这个单词是不是不对,检查的比对文本就是训练的数据。如果预测错了(算法刚开始训练的时候几乎都是错的),它会改变自己的内部算法结构。渐渐的,算法就学会了预测的技巧,然后预测的结果就变得越来越好。
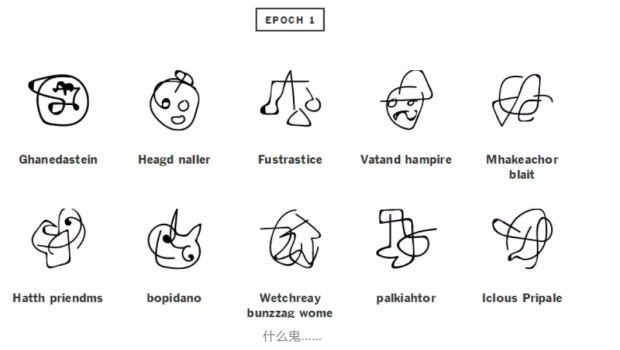
为了直观感受一下,下面这张图是textgenrnn神经网络在不同的训练阶段所生成的文字结果。这里所说的不同阶段就是训练中的不同的epoch,就是迭代了几次的意思。(它只能生成文字,不能生成图片,为了让生成的文字更直观,我们请来了灵魂画师对其进行灵感作画)

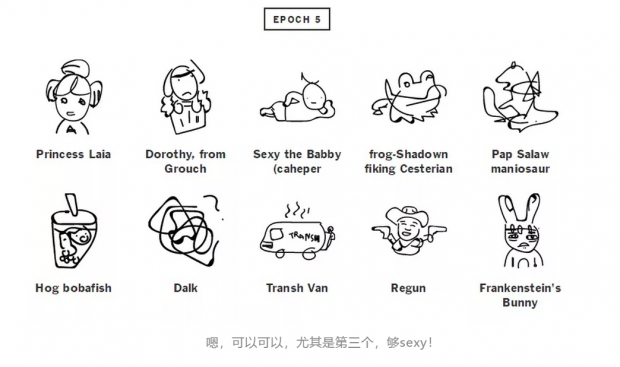
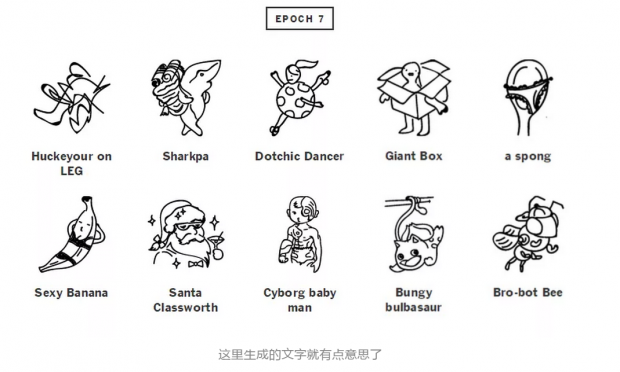
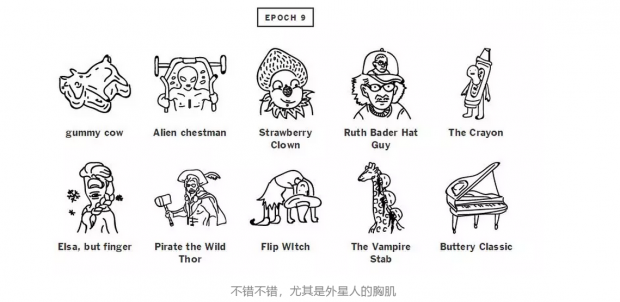
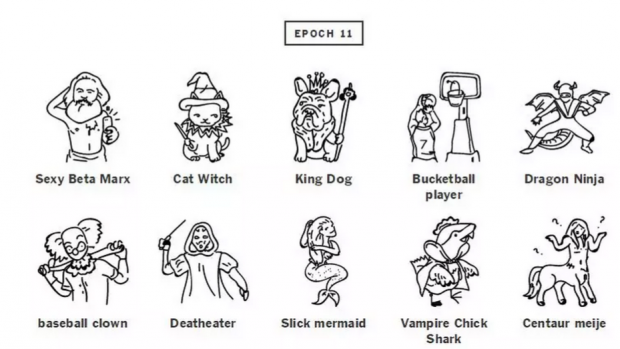

11次迭代就已经很棒了,大概能知道是什么了,猫巫好萌!
当我们让算法生成服装名称的时候,我们还可以给它设置一个“创造性”选项。如果给它的创造性空间比较小的话,它总是根据自己的最好的预测生成一些重复的结果;
如果我们给它“自由过了火”的话,它会冒险进入一些它认为不太可能的领域里面然后输出一些奇奇怪怪的东西。
在训练刚开始的时候,神经网络对于输入的内容一无所知。它不知道英文字母和空格是有区别的,也不知道一个文字是怎么拼写的。当训练迭代的次数增加,它就能学到一些事情了。嗯,当然了,鉴于万圣节定制服装这帮人的癖好,算法妥妥学到的第一个单词是……“sexy”(性感)。
在训练的过程中,算法学到了各种词汇,比如说“steampunk(蒸汽朋克)","minion(小兵)","cardinalfish(一种鱼)","Bellatrix(对对对,哈利波特里杀死多比的那个粉底抹多了的女巫)"。它学会了这些之后就不务正业了,开始在各种刺激的地方加上“sexy”这个词,包括一些训练数据里根本没出来过的情况,比如:
灵魂画手辣眼睛……依次是性感的路易十六、性感的麦克赛拉、性感的打印机、性感的大x蜂、性感的锡人、性感的林肯、性感的甜菜、性感的Minecraft人?!来,请告诉我性感的打印机是怎么回事儿,怎么还有马赛克!嗯。。。林肯的胸毛确实很性感,还有甜菜的沟沟。
算法也可以直接从训练数据集里拷贝一些结果出来。如果我们允许这样的操作的话,算法的确会这样输出。其实对于算法来说,这样拷贝出的结果肯定是最完美的(因为肯定真实)。
算法知道的所有知识都来自于训练集,它没有别的信息来源。比如说,它不知道今年有什么热门电影,所以它还是会输出一大堆“Pink Panther(就是那个粉红豹子表情包)”,而不是时下更热门的漫威电影“Black Panther(黑豹)”。当然这个算法还会自造词,比如弄出来一些类似于“Fary Potter”和“Werefish”的词汇。造这些词的时候其实不是因为算法已经理解了单词的意思,而是因为单纯的觉得这个词是万圣节服装订单里的内容,觉得它是个合理的单词组合。
其实,这就是神经网络和其他机器学习算法看起来有点可怕的地方:人很难预测模型会弄出来什么样的组合。比如它会输出一些“Bloody Horse”(血淋淋的马),“Gothed Pines”(哥特式松树)和“Ballerina Trump”(跳芭蕾舞的川普,干得漂亮!)。虽然我们能够去在算法级查阅每一层神经元在干什么,但是,仍旧无法对其进行解释。
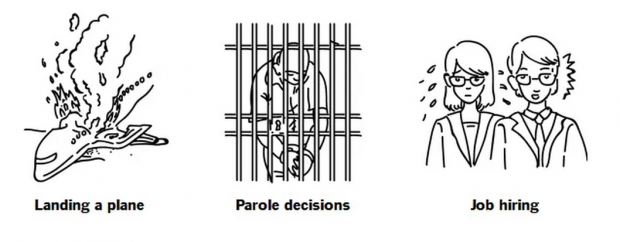
人类现在正在研究算法的解释性,比如说,谷歌和CMU的大佬们最近展示了他们的研究成果,就是用一个识别耳朵的算法去识别狗。但是很多算法还是很难解释,比如说那些辅助做贷款和假释的决策算法,这些算法在现在看起来就是一个黑盒,根本无法解释怎么就能让它允许贷款,怎么就提高假释的概率。
有时候,算法会产生一些灾难性的后果。2013年的时候MIT的研究人员做了一个算法来解决数字列表的排序问题。人类告诉算法说,目标是减小序列中的顺序错误。
你以为算法会创造出一种新型的快速排序?不,它把所有数字都删了……(真聪明,这样真是没有任何顺序错误了)。然后在1997年的时候,为了让飞机在航母上降落的更柔和,研究人员做了一个飞机降落算法。
然后在模拟里面,飞机降落时候对航母的冲击结果是0,人们惊呆了,以为发现了什么不得了的事情。但是查过了之后才发现,算法是让飞机以一种极大的冲击力撞击航母,然后这个力太大,导致模拟器中存储力量数值的变量存储溢出了,所以得到一个0……(人才呀,这撞的得多寸)
排序例子的详情戳这里:
降落算法的详情戳这里:
面对一个人类根本不了解的算法给出的决定,我们通常都很难接受。但是其实机器学习算法都是从数据集里面学的,就算学到了特别奇怪的东西,也是人类的偏见。
换句话说,机器学习返回给我们的,都是我们想要的,不论是好还是坏。
比如说,当一个算法从一个数据集里面学习一个人被雇佣的概率的时候,如果数据集里面就包含了种族偏见(比如某公司更喜欢雇佣某人种的员工)的话,那么算法肯定也会带有这个偏见进行预测。毕竟我们并没有告诉算法最好的决策是怎样的,我们只告诉它数据集里面是怎么做的了,而数据集里的样本体现的很可能不是最好的结果。
雇佣员工的算法例子详情戳这里:
这种错误随处可见,算法中有偏见也是常有的事。我们说这个故事的寓意不是想让AI更公平公正,也不是想让AI能给我们提供达成目标的小线索。我们真正想说的是,AI只能返回我们请求的事件的结果,所以我们应该仔细思考和选择我们请求事件的类型和方式。比如来说,我们不该在没有仔细校验的情况下就将那个以强烈撞击导致数值溢出而使冲击力=0的算法实际应用到灰机上。
同样,如果我们这个万圣节服装预测模型要是输出很多奇奇怪怪的服饰的话,我们也还是别信的好(比如说有人穿Spirit of Potatoes你敢信?!土豆侠?我天,我第一反应是植物大战僵尸里面的坚果兄)。
注:土豆侠……啊……说到这的时候,译者在翻译的时候突然听到金庸先生去世的消息,心情沉痛。飞雪连天射白鹿,笑书神侠倚碧鸳。先生千古。
想看更多的算法错误和偏见戳这里:
相关报道:

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}