
作者:钱天培、Aileen
今年的NeurIPS(原名NIPS)会议开幕了!
开幕式上公布了4篇最佳论文,其中一篇最佳论文一作来自华为诺亚方舟实验室,另外几篇最佳论文被来自多伦多、谷歌AI的研究者包揽。
本次NeurIPS大会一共有6个Poster部分,3个并行的主方向,历时三整天。在开始销售门票后的短短11分钟28秒后,所有的参会资格就已被抢购一空,一票难求,盛况空前。
昨天大会的第一日,阿里巴巴霸气演示全中文demo,以及谷歌联合NeurIPS发布“找新娘图片识别竞赛”也算是为接下来的精彩抛砖引玉。
附上大会直播链接:

与去年一样,今年也评出了4篇最佳论文奖,当然,还有一篇时间检验奖。
四篇最佳论文(Best Papers)
四篇最佳论文(Best Papers)

摘要:我们介绍了一系列新的深度神经网络模型。我们使用神经网络参数化隐藏状态的导数,而不是指定隐藏层的离散序列。我们使用黑盒微分方程求解器(black-box differential equation solver)计算网络的输出。这些连续深度模型具有恒定的内存成本,根据输入采取相应的评估策略,并且可以直接通过降低数值精度来提升速度。我们在连续深度残差网络(continuous-depth residual networks)和连续时间潜变量模型(continuous-time latent variable models)中证明了这些性质。我们还构建了连续归一化流(continuous normalizing flows),这是一种可以通过最大似然进行训练的生成模型,无需对数据维度进行分区或排序。对于模型训练,我们展示了如何通过任何ODE求解器进行规模化地反向传播,而无需知道其内部操作。这允许我们在较大模型中对ODE进行端到端训练。

摘要:我们证明了Θ(kd^2 /ε^2)个样本对于学习d维下的k个高斯混合模型(mixture of k Gaussians)是必要充分的,这里我们允许总变差距离(total variation distance)误差在ε以内。这一结果对该问题的已知上限和下限作出了改进。对于轴对齐高斯分布的混合(mixtures of axis-aligned Gaussians),我们证明O(kd /ε^2)个样本就足够了,这与已知下限相符。对于上限,我们提出了一种基于样本压缩概念的分布式学习的新技术。对于允许这种样本压缩方案的任何分布,我们都可以用很少的样本来学习。此外,如果一类分布具有这样的压缩方案,那么这些分布的乘积或混合也同样可以运用这种方案。我们主要结果是表明了d维下的高斯类具有有效的样本压缩。

这篇文章的5位作者中:Kevin Scaman来自华为诺亚方舟实验室,Francis Bach和Laurent Massoulié来自巴黎文理研究大学、Sébastien Bubeck以及Yin Tat Lee来自微软研究院。
摘要:在这项工作中,我们使用一个计算单元网络,对非光滑凸函数进行了分布式优化。我们在假设下研究这个问题:(1)全局目标函数的Lipschitz连续性,以及(2)局部个体函数的Lipschitz连续性。在局部性假设下,我们提出了第一个最优一阶分散算法,称为多步原始对偶(multi-step primal-dual,MSPD),及其相应的最优收敛速度。该结果的一个值得注意的方面是,对于非平滑函数,当误差的主导项为O(1 /√t)时,通信网络(communication network)结构仅影响O(1 / t)中的二阶项,其中t是时间。换句话说,即使在非强凸(non-strongly-convex)目标函数的情况下,由于通信资源(communication resources)中的限制而导致的误差也会以较快的速率降低。在全局性假设下,我们提供了一种简单而有效的算法,称为基于目标函数局部平滑的分布式随机平滑(distributed randomized smoothing,DRS),并表明DRS和最优收敛速度只差一个d^(1 / 4)的乘法项,其中d是维度。

摘要:我们确定了Q-learning和其他形式涉及近似函数(function approximation)的动态规划中的基本误差来源。当近似架构限制了可表达的贪婪策略的类别时,妄想偏差(delutional bias)就会出现。由于标准Q-updates对可表达的策略类别进行全局不协调的行动选择,因此可能导致不一致甚至冲突的Q-value估计,从而出现诸如估计过高/过低,不稳定甚至不收敛的各种问题。为了解决这一问题,我们引入了一个新的策略一致性(policy consistency)概念,并定义了一个局部备份(local backup)过程,通过使用信息集来确保全局一致性,这些集合记录了与备份Q-value一致的策略约束。我们证明了,不管是基于模型的还是不基于模型的算法,都可以使用这一“备份”的方法来消除妄想偏差(delutional bias),从而提出了第一个可在一般条件下保证最佳结果的算法。此外,这些算法仅需要的信息集数量只是多项式级别的。最后,我们也提出了关于价值迭代(value iteration)和Q-learning在实际应用中的几个小建议,这些建议都可以被用来减少妄想偏差(delutional bias)。
时间检验奖(Test-of-time award)
时间检验奖(Test-of-time award)
这篇论文是出自2007年,作者是Leon Bottou和Olivier Bousquet,分别来自NEC美国实验室和Google。
摘要:该研究开发了一个理论框架,用以研究近似优化对学习算法的影响。该分析显示了小规模和大规模学习问题在这方面的明显不同。小规模学习问题受到常见的近似估计权衡(approximation–estimation tradeoff)的影响,而大规模学习问题则受到其对应的优化问题计算复杂性的严重影响。
注:今年大会全部论文
会议整体情况
会议整体情况

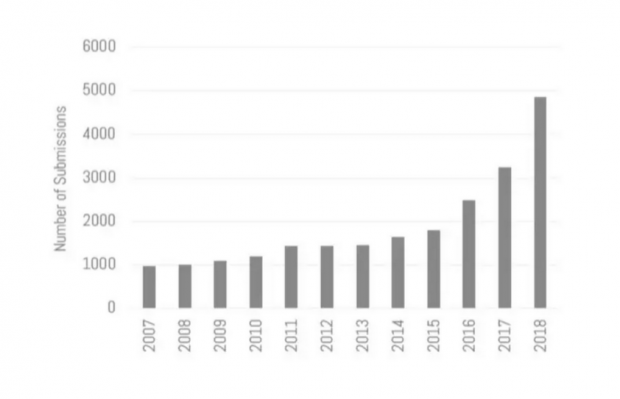
总共有4854篇论文提交,相比去年增长了50%,也是今年ICML投稿数的两倍。这些论文中,26%为重新提交稿件,69%的论文公开了代码,42%的论文公开了数据。
另外,3045个论文评审员 (比往年增长45%)、242个领域主席(比往年增长32%)、35个高级主席(比往年增长35%)(高级主席不受双盲限制)、1万5千篇论文评论(大约每篇文章3篇评论)、85%的评论表示,对该论文的可复制性有信心。
论文接受情况:1010篇论文被接收(比往年增长49%),其中,30篇论文被分到了oral presentation,168篇为spotlight,812篇论文被分到了poster presentation。
整体接收率为21%,与去年持平。其中,此前未在网上(arxiv)发表的论文的接收率为16%,低于整体接收率。在网上发表、但未被评审员看到的论文接收率为20%。最后,在网上发表、并被评审员读到的论文接收率高达34%。
在被接收论文中,25%是重新提交稿件,55%的论文已在arxiv上发表,其中35%的论文在此前被评审员读过。另外,44%的论文提供了代码或数据。
在公布完这组数据后,主持人也提醒大家不要过度解读。
针对今年广受诟病的visa问题,大会也非常直接的提出了回应,并指出了改正方法:

大会公布了接下来的主席和联合主席:


0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}