阅读:0
听报道

5分36秒,10:1,人类完败。
这是在星际争霸游戏中,DeepMind AI——AlphaStar对战人类的最新战局。
一共11场比赛,其中10场是事先录制的,只有1场是现场交手。现场交手的双方是AlphaGo的“哥哥”AlphaStar与 2018 WCS Circuit排名13、神族最强10人之一的MaNa。在11场比赛中,也只有现场交手这一次,由于比赛限制了AI的“视觉”能力,MaNa帮人类赢了一场。
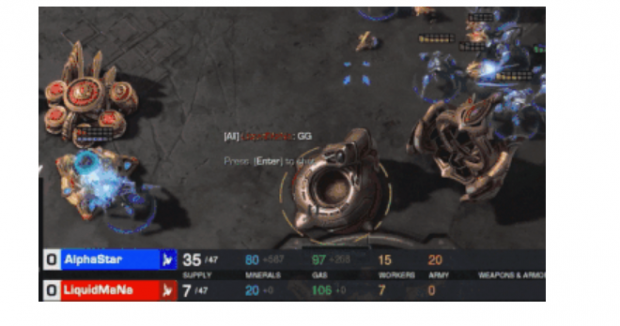
另外10场比赛,代表人类出战的是职业选手TLO和MaNa。两位选手分别与AlphaStar打了五场。如果说与TLO对战时AlphaStar还是萌新的话,那么与MaNa的对战则完全显示出了其战术的老辣。毕竟,两个比赛才相隔2周,AI 自学成才的能力已经初步显示了可以超越人类极限的潜力。
比赛的录像,DeepMind也在其官网给出,星迷们可以通过下面的链接回顾赛事。
()
比赛概况
前10场分别是在12月份的BOD赛举行的,比赛地图是Catalyst,中文名叫“汇龙岛”。比赛所采用的版本也是专门为了进行人工智能研究所开发的。虽然TLO在比赛之前表示完全有信心打败AI,但是不得不说,5场比赛中AI独特的战术似乎让TLO始料不及,最后TLO以5:0输掉比赛。

AlphaStar在对抗TLO的时候在比赛制度的设置上还是有些优势。首先,这场比赛双方都只能使用Protoss(神族),这并非TLO主族(在天梯上,职业玩家的主族和副族之间往往相差一千分以上)。此外,AlphaStar与普通玩家的比赛视角不同,虽然AI也受到战争迷雾的限制,但它基本上可以看到整个小地图。这意味着它可以快速处理可见的敌方及其自身基础的等信息,所以其不必像人类玩家那样将需要将时间分配到地图的不同区域。
在今天的现场直播中,比赛限制了AI的“视觉”能力,MaNa对战AlphaStar,帮人类玩家拿下一胜,“一雪前耻”。这也显示虽然AlphaStar仅仅经过几周的自我学习就能与顶级玩家交手,但也存在很多漏洞和可以改进的地方。
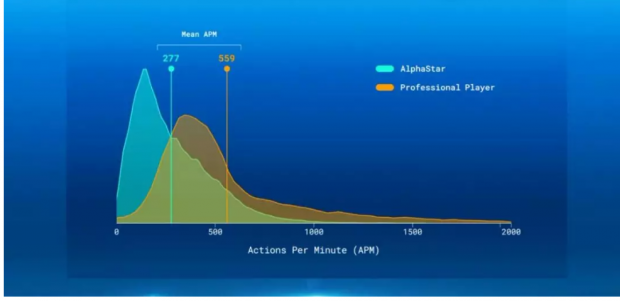
尽管如此,AlphaStar并没有如人们想象的那样,从优势中获得大的收益。虽然在理论上TLO和MaNa在游戏中的APM不如AI快,但AlphaStar实际上每分钟执行的操作数比他的人类对手还少,并且明显少于普通职业玩家的操作次数。AI也有大约350毫秒的反应时间,显然这比大多数职业玩家要慢。不过,整体来看,虽然人工智能花费了更多时间,但却能够做出更聪明,更有效的决策,从而更占优势。
AlphaStar:用一周玩了200年的星际争霸II
AlphaStar在游戏中的专业能力主要来自DeepMind称之为AlphaStar联盟的深入培训计划。DeepMind通过重播大量的人类游戏录像,并基于这一数据训练神经网络。由人类数据组成的代理分叉创建新的对手,并且这些竞争者在一系列比赛中相互匹配。同时,鼓励原始数据的那些分支去学习特殊技能,并掌握游戏的不同部分以创造独特的游戏体验。
AlphaStar联盟运行了一周,每场比赛都产生了新的信息,有助于改进AI的战略。在那一周,AlphaStar相当于玩了整整200年的星际争霸II。结束时,DeepMind选择了五个最不容易被利用、获胜几率最高的agent对战TLO,在5场比赛中全部胜利。

看到人工智能成功地打败非对手,DeepMind决定让AlphaStar对抗神族专家MaNa(虽然在职业赛场上MaNa这样的欧美籍草鸡神族并不代表人类的最高水平和最先进的战术体系)。AlphaStar在比赛前进行了另一周的训练,吸取了包括在和TLO比赛中所获得的知识。评论员们指出,人工智能在比赛中发挥得更像人类,在调整决策和风格的同时放弃了一些比较不稳定和意想不到的行动。
就像他之前的TLO一样,尽管MaNa表现出了十足的英勇,但仍然在每场比赛中都输给了AlphaStar。人工智能再次赢得了所有五场比赛。这场人机大战,在与职业人类选手的前10场比赛中以10比0结束。
在播放录制的比赛后,DeepMind推出了新版AlphaStar,MaNa在现场直播中和再次与AI交锋。这一次 AlphaStar无法享受头顶摄像头的好处,它必须决定将视线焦点放在哪里(像人类玩游戏的方式一样)。 DeepMind表示,在一周之内AlphaStar已经快速掌握了游戏的新视觉观感,但还没有机会在对阵MaNa之前和人类专业玩家进行测试。
随着对AlphaStar视觉观感的新限制,MaNa能够利用AI的一些缺点并取得胜利,所以AlphaStar输给了人类玩家。
AlphaStar在整场比赛中展示了令人印象深刻的微操作能力。很快将受损的部队移回,将较强的部队带入战斗的前线。AlphaStar还控制着战斗的速度,让单位前进并在正确的时间略微回拉以造成更多伤害,同时减少收到的伤害。这不是APM的优势,与人类玩家相比,AlphStar的APM反而更低。AlphaStar的优势主要在于更优化的策略和更聪明的决定。
确实,AlphaStar的专业水准与在游戏上的学习速度对每一位星际玩家来说可能都不是什么好消息。但是,在游戏领域,游戏玩家可以从AI身上学到非常多有用的策略。
星际争霸——挑战人类智力的游戏
“星际争霸II”由暴雪娱乐公司制作,以虚构的科幻宇宙为背景,具有丰富的、多层次的游戏体验,其目的在于挑战人类的智力。超过20年的时间里,玩家们连续不断的举办比赛,参加比赛,在赛场上抛洒热血。
这个游戏有几种不同的游戏模式,比赛中最常见的是1v1比赛。首先,玩家必须选择玩三个不同的外星“种族”,即虫族,神族或人族,每一个种族都有独特的能力和特点。每个玩家开局都会有控制单位,通过收集基本资源来构建更多的单位,从而开发新的战术和技能。通过新的战术和技能收集新的资源,建立更加牢固、复杂的基地。如此循环往复,直到打败对手为止。
所以说,要想获胜,玩家必须有全局把控能力,强大的战略布局能力以及对单个单位的“微观”控制能力。
玩游戏的过程中,要做到短期目标和长期目标的兼容。还需要强大的灵活调整能力,能够应对游戏过程中的突发情况。为了解决这几点,总的来说,人工智能的需要突破的技术点是:
博弈论:星际争霸是一种像石头剪刀一样的游戏,没有单一的最佳策略。因此,在对人工智能进行训练的时候,需要不断探索战略层面的知识。
不完全的信息:在国际象棋或围棋这种棋牌游戏中,玩家可以对比赛一览无余。在星际中,玩家关键的信息是隐藏的,必须通过“侦察”才能发现。
长远布局:和许多现实世界的问题一样,因果关系并不是那么容易达成。在游戏的任何地方你都可以花费时间,但这也意味着在游戏早期采取的行动可能在很长一段时间内没有回报。
实时:不同于传统棋盘游戏,玩家轮流行动,星际争霸玩家必须在游戏中不断进行操作。
巨大操作空间:必须实时控制数百个不同的单元和建筑物,从而形成巨大的可能性组合空间。除此之外,操作是分层的,可以修改和扩充。 对游戏的参数化允许在每个时间步长平均有大约10到26个合法操作。
由于这些难点,星际争霸已成为人工智能研究的“巨大挑战”。星际争霸和星际争霸II正在进行的比赛评估了自2009年BroodWar API推出以来的进展,包括AIIDE星际争霸AI比赛,CIG星际争霸比赛,学生星际争霸AI比赛和星际争霸II AI 排名赛。为了帮助社区进一步探索这些问题,在2016年和2017年与暴雪合作发布了一套名为PySC2的开源工具,包括迄今为止发布的最大的匿名游戏回放集。我们现在在这项工作的基础上,结合工程和算法的突破制造了AlphaStar。
AlphaStar怎么训练的
AlphaStar的工作原理是首先获取原始游戏数据,并通过游戏中复制的指令学习游戏规则。但是为了理解如何玩,DeepMind必须做大量的训练。
为AlphaStar提供支持的神经网络学习了暴雪公司提供的约50万场匿名人类真实游戏。然后AlphaStar能够通过模仿学习策略,虽然它只是观察人类如何玩游戏。很快,该项目可以在95%的游戏中击败“精英”级游戏AI。
然而,这些信息用于训练各种Agent,每个Agent在一个庞大的虚拟AlphaStar联盟中相互竞争。人工智能与人工智能对决,只为了一个目标:精通游戏。
这项技术被称为多智能体强化学习过程,通过集体经验学习。随着新的Agent加入到联盟中,他们分叉并参与越来越多的比赛,通过强化学习在每个阶段采用新策略,同时不忘记如何击败早期的策略。
随着联盟的扩大,新战略开始出现。然后,随着时间的推移,这些策略的反制策略被开发出来,直到该计划在获得了在战术上对如何获胜的不同的理解,无论其在游戏中面临的怎样具体的挑战。在AlphaStar联盟的早期比赛中,该计划偏爱有风险的“All-in”战略。但是,随着时间的推移,它学会了更具战略性,每个Agent实际上都在试图击败它之前看到的每一个Agent。
联盟中的每个Agent也有自己的目标:例如,一个可能需要击败一种竞争者,而另一个可能需要通过使用特定的游戏单元来专注于获胜。联盟运行了14天,每个AI Agent使用16个张量处理单元(谷歌的AI芯片组)。总体而言,每个Agent经历了长达200年的实时星际争霸游戏,并且数千个并行运行的游戏实例。
最终的AlphaStar Agent将通过数千小时游戏玩法发现的所有最佳策略的精华融入到可以在单个桌面GPU上运行的程序中。
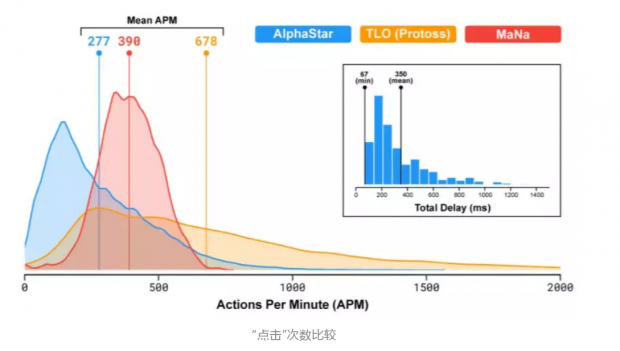
除了复杂性,星际争霸挑战对人工智能系统的主要吸引力还在于它的广泛性和竞争性。在众多竞赛中,有超过240万名玩家,因此DeepMind能够在大量数据上训练AlphaStar。在基准测试中,它每分钟能够执行大约280个动作,远低于专业人类玩家可以实现的动作,但是,重要的是,DeepMind认为,AlphaStar更精确。这也反映在了对抗人类对手的比赛中,例如,在对阵Wünsch的第一场比赛中,AlphaStar每分钟完成277次动作,而人类玩家则为559次。AlphaStar轻松赢得了比赛。
这一点为什么重要呢?DeepMind希望这些通过研究星际争霸所完成的无数突破可以扩展到其他不那么琐碎的应用当中。
例如,AlphaStar的神经网络架构可以模拟和理解可能行为的长序列,并使用混乱和不完全的信息来实现。在视频游戏中,这允许AI快速找到获胜策略并在必要时进行调整。在现实世界中,基于大量数据进行复杂的预测是人工智能的基本挑战。
AlphaStar所取得的成就在这一挑战中向前迈出了重要一步。该计划能够在星际争霸中取得优异成绩,以后也可能有助于更精准的天气预报,气候建模和语言理解。“我们对利用AlphaStar项目的学习和发展在这些领域取得重大进展的潜力感到非常兴奋,”DeepMind团队表示。
拭目以待!
相关报道:
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}