从足球竞技到战争,团队合作一直被认为是人类社会进步的基石。基于长远的共同目标,弱化甚至牺牲个人利益,促成了人类作为共同体的最大利益。
DeepMind也正尝试让人工智能学会这一点,并且选择了最有可能显示团队合作的考核方式——足球比赛。
今天凌晨,DeepMind发布了最新研究:证明了在足球环境下,一种基于分布式代理的连续控制培训框架,结合奖励渠道的自动优化,可以实现多智能体端到端的学习。
简单来说就是,DeepMind设置了环境,让多个AI一起踢足球赛。并且提前设置了规则,奖励整只“足球队”而不去鼓励某个"AI球员”的个人成绩,以促成整个球队的进步。用这种方式证明了,AI也是可以相互合作的!

先附上论文链接:
这篇论文被ICLP 2019收录。
通过竞争,实现紧急协调的多方协作
通过竞争,实现紧急协调的多方协作
多智能体通过协作,完成团队最优目标并不是一个陌生的话题,去年,OpenAI就曾发布了由五个神经网络组成的DOTA团战AI团队——OpenAI Five(超链接),并在5v5中击败了顶级人类玩家团队。比赛中,OpenAI Five也展示了,在胜利是以摧毁防御塔为前提的游戏中,牺牲“小兵”利益是可以被接受的,也就是说,AI是可以朝着长期目标进行优化的。
DeepMind的最新研究进一步专注于多智能体(multi-agent)这一领域。
他们组织了无数场2v2的AI足球比赛,并设定了规则,一旦有一方得分或者比赛超过45秒,比赛就结束。

DeepMind称,通过去中心化的、基于群体的训练可以使得代理人的行为不断发展:从随机,简单的追球,到最后的简单“合作”。他们的研究还强调了在连续控制的大规模多智能体训练中遇到的几个挑战。
值得一提的是,DeepMind通过设置自动优化的简单奖励,不鼓励个体,而去鼓励合作行为和团队整体的成绩,可以促成长期的团队行为。
在研究中通过引入一种“基于单独折扣因子来形成自动优化奖励的思想”,可以帮助他们的代理从一种短视的训练方式,过渡到一种长时间但更倾向于团队合作的训练模式当中。
DeepMind也进一步提出了一个以博弈论原理为基础的评估方案,可以在没有预定义的评估任务或人类基线的情况下评估代理的表现。
具体思想
具体思想
将足球比赛看做一个多智能体强化学习(MARL)的过程,模拟一个可交互的环境,智能主体通过学习与环境互动,然后优化自己累计奖励。MARL的主题思想是协作或竞争,亦或两者皆有。选择什么样的行为,完全取决于“报酬奖励”的设置。MARL的目标是典型的马尔科夫完美均衡。大致意思是寻找随机博弈中达到均衡条件的混合策略集合。
具体意思是:博弈参与者的行动策略有马尔科夫特点,这意味着每个玩家的下一个动作是根据另一个玩家的最后一个动作来预测的,而不是根据先前的行动历史来预测的。马尔科夫完美均衡是:基于这些玩家的动作寻找动态均衡。
DeepMind在github上发布了他们使用的MuJoCo Soccer环境,这是一个竞争协作多智能体交互的开源研究平台,在机器学习社区已经得到了相当广泛的使用。
github地址:
评估
评估
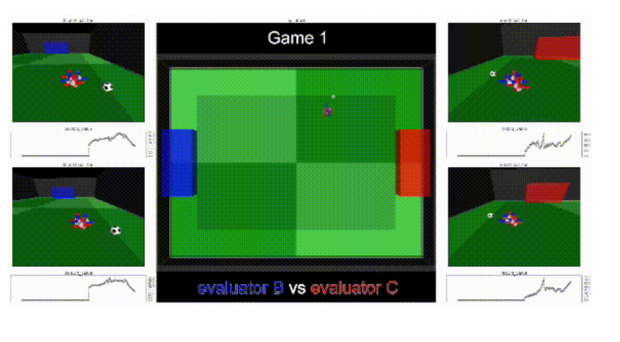
相关比赛视频链接:
为了有效地评估学习团队,DeepMind选择优化评估方法,所选团队都是以前由不同评估方法产生的10个团队,每个团队拥有250亿次的学习经验。他们在10个团队中收集了一百万种比赛情况。
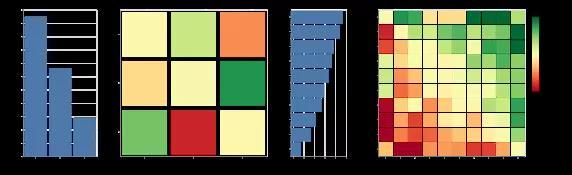
上图显示了支持团队的3个智能体显示的成对预期目标差异。纳什均衡要求3个团队的权重都是非零的,这些团队协作展示了具有非传递性能的不同策略,这是评估方案中并不存在的:团队A在59.7%的比赛中赢得或打平团队B; 团队B在71.1%的比赛中赢得或打平团队C,团队C在65.3%的比赛中赢得或打平团队A.,他们展示了团队A,B和C之间的示例比赛的记录,可以定性地量化其策略的多样性。
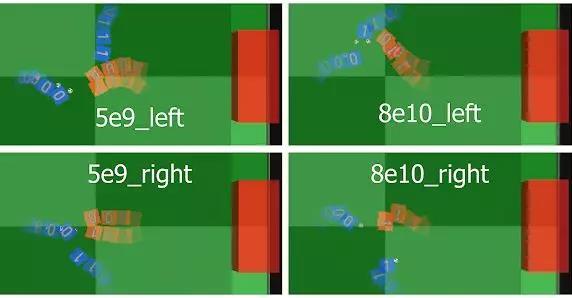
在上图中,DeepMind展示了代理行为的典型轨迹:在5B步骤中,当代理更个性化地行动时,我们观察到无论blue1的位置如何,blue0总是试图自己运球。但在训练的后期,blue0则积极寻求团队合作,其行为呈现出由其队友驱动的特点,显示出高水平的协调精神。特别是在“8e10_left”这一场比赛中中,DeepMind称他们观察到了两次连续传球(blue0到blue1和后卫),这是在人类足球比赛中经常出现的2对1撞墙式配合。
未来研究
未来研究
DeepMind此项研究意义重大,将2v2足球领域引入多智能体协作是以前没有过的研究,通过强化学习研究,利用竞争与合作来训练独立智能个体,展示了团队的协调行为。
这篇论文也证明了一种基于连续控制的分布式集群训练框架,可以结合奖励路径自动优化,因此,在这种环境下可以进行进行端到端的学习。
其引入了一种思想,将奖励方向从单策略行为转变为长期团队合作。引入了一种新的反事实政策评估来分析主题策略行为。评估强调了匹配结果中的非传递性和对稳健性的实际需求。
DeepMind开源的训练环境可以作为多智能体研究的平台,也可以根据需要扩展到更复杂的智能体行为研究,这为未来的研究打下坚实的基础。


0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}