阅读:0
听报道
作者:蒋宝尚、魏子敏
先做一个简单的小测试。
这里有几组图片,不要怀疑,每组图片都有一张是合成的“假脸”。

左边为假

右边为假

左边为假
StyleGAN:图片生成新神器
上面的那三组图片来自最近在reddit上爆火的一个网站——“哪张脸是真的(which face is real?)”,网友们非常热情地将结果在网站上进行比拼,并贴出了测试结果。
你可以打开下面的网址,自己进行更多的图片识别测试
生成对抗网络(GAN)自从2014年Ian Goodfellow提出之后,到今天已经发生了天翻地覆的变化。
早期生成的图片还非常“辣眼睛”,远不能骗人。比如2004年的这批“假脸”。

但是经过十多年的发展,现在生成的图片已经和真实的相差无几了,不是老司机根本识别不出来。
比如说你在文章开头看到的几组图片。说真的,文摘菌在刚刚开始玩的时候几乎全靠“蒙”!有几次甚至觉得假脸比真的脸还要逼真。
看了下相关介绍,果然,网站上所采用的图片全部是用StyleGAN生成的。
StyleGAN来自英伟达,可以说是近期火遍全网的“造假”神器了。与其他生成器不同,StyleGAN可以根据需要更改生成图像的结果,绘制出的图片更加逼真,不仅可以创造假的人类肖像,也被疯狂应用于其他机器学习应用项目,例如汽车、房间、甚至是动漫人头等。
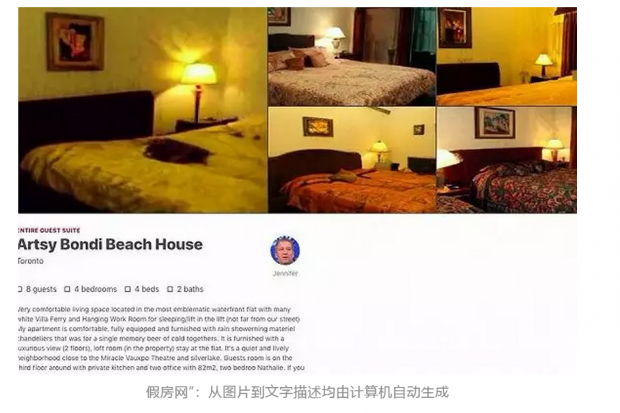
上图是在Reddit最近也颇多人讨论的”假Airbnb”网站“,它也是由StyleGAN生成的,网站上的图片和文字所描绘的根本不是实物。
网站地址:
这只假房生成网站每次刷新都会出现一个虚假的房源,网页上的照片、文字描述、发布的人头像均由计算机自动生成。由于使用的模型非常简单,文字描述多有不合逻辑之处,但猛地一看还是能以假乱真。
StyleGAN最初是由英伟达在一篇论文中《一种用于生成式对抗网络的基于生成器体系结构的方式(A Style-Based Generator Architecture for Generative Adversarial Networks))

论文下载地址:
据论文介绍,StyleGAN是一步一步地生成人工图像的,从非常低的分辨率开始,一直到高分辨率(1024×1024)。通过分别地修改网络中每个级别的输入,它可以控制在该级别中所表示的视觉特征,从粗糙的特征(姿势、面部形状)到精细的细节(头发颜色),而不会影响其它的级别。
这种技术不仅可以更好地理解所生成的输出,而且还可以产生最高水平的结果,即比以前生成的图像看起来更加真实的高分辨率图像。
所以说,StyleGAN是一篇突破性的技术,它不仅可以生成高质量的和逼真的图像,而且还可以对生成的图像进行较好的控制和理解,甚至使生成可信度较高的假图像变得比以前更加的容易。在StyleGAN中提出的一些技术,特别是映射网络和自适应实例标准化(AdaIN),可能是未来许多在GAN方面创新的基础。
“打假”有术!识别假图片小技巧
这么逼真的假图片,就没有办法识别了么?别慌,再聪明的AI在造假时,都还是会留下一些痕迹。专业的研究者们一边造假,一边也给大家留下了一些“打假”小技巧。
斑点
StyleGAN算法虽然厉害,但是有个显著的特点,就是生成的图片往往会有闪亮的斑点,虽然这些斑点看起来像是照片放久了,化学反应的产物,但是这确是这些合成图片致命的缺点。
这些斑点可以出现在图片的任何地方,头发以及背景区域出现的概率最大。

背景问题
另一个致命的缺点会出现在照片的背景图上,神经网络在对人物图像的面部进行识别的时候,往往不会非常重视。在一些情况下,照片的背景会显得非常的凌乱,不要多想,这并不是印象派的画作,是神经网络在生成图片的时候,对背景处理的不够好。

眼镜
即使StyleGAN已经非常强大,但是和他的前辈们一样,同样无法完美的处理眼镜,最常见的问题是眼镜的两边不是对称的。就拿框架来说,通常合成的图片,左边的框架风格和后边的框架风格不太一样,如下图,框架的一侧有时候会出现弯曲以及锯齿状。

其他不对称问题
除了眼镜之外,有些时候面部毛发也会出现不对称问题。左耳和右耳佩戴的耳环也不一样,以及衣领在左右两侧也会出现不同的形状。

现在,对称性往往是人脸生成算法的一大挑战,我们完全可以利用它的这个弱点,对其一击致命。
头发
一般来说,合成的人物图片,头发往往都不会很逼真, 有时在脸上或其他地方头发会断开,如下第一张图所示,有的时候人物的头发会太直,以及会呈现条纹状。正如Kyle McDonald 所说,就像有人用调色刀弄乱了一堆丙烯酸树脂。在一些情况下,头发周围可能出现一些奇怪的光圈或者光晕,如中间那张图所示:

背景荧光
另一个有趣的缺点是,荧光颜色有时会从背景出现到头发或面部。

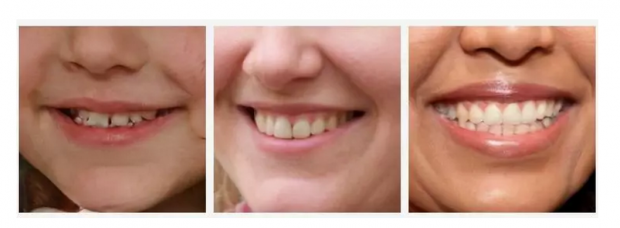
牙齿
牙齿不容易渲染。 通常牙齿是奇数或不对称的。 在某些情况下,合成的人物图片会出现三颗大门牙。
如果你仍然对GAN生成的图片感到恐惧,文摘菌曾经写了更详细的文章《GAN生成的假脸太逼真了!别怕,十招教你识别AI生成的假图像》来帮你识别假照片,戳这里获得更多技巧。
好了,现在你应该知道神经网络很难生成什么东西了吧,你可以像找玩找茬游戏一样,找到每张合成图片的致命缺点,培养你对识别真实图片的信心。
“打假”技能考核开始
看完这些技巧,再来测试一下各位的打假能力吧,再来测试几组图片,看看你的“看图”能力是否提高

左边是假的,注意头发光圈

右边是假的,注意凌乱的背景

右边是假的,注意光斑
“打假”网站从何产生?

最后,也为大家再介绍一下,这个有趣的“打假”网站是怎么诞生的。
这个项目来自华盛顿大学的一门网红课程“抵制狗屁——calling bullshit。授课老师分别是生物系的Carl Bergstrom和信息学院的Jevin West。
这门课火起来部分来自这个桀骜不驯的名字,至于为什么叫“bull shit”,课程介绍是为了抵制目前存在的各种bullshit信息,包括公然罔顾事实和逻辑的语言、数据、图表,以及其他呈现方式。
当然,在这个粗俗的课名之下,是非常严肃的课程设置。
两位老师在课程网站的教学大纲页面公布了全部的课程内容和阅读材料。感兴趣的朋友可以仔细阅读。以下我做一个简单的介绍和分析。
教学大纲:
在引言部分,课程使用的是普林斯顿大学教授Harry Frankfurt的文章《On Bullshit》。其实他出版了一本书就叫《On Bullshit》。南方朔将其翻译成了中文,在台湾出版的时候用的书名是《放屁!名利雙收的捷徑》,在大陆出版的时候则用了非常保守的译名《论扯淡》。
第2周引入了一些常见的分辨狗屁的方法。第3周介绍的是孕育狗屁的生态系统,比如社交媒体如何促进了狗屁的传播。
接下来的几周,课程从统计学和逻辑的角度切入,具体分析了一些狗屁的类型,包括混淆相关性和因果关系、中位数和平均数、“检察官谬误”等。课程还单独辟出一周介绍了数据可视化中常见的误导。
第7周的大数据部分,关注的是在大数据和算法的光鲜外表之下,“垃圾进、垃圾出”的现象,以及对机器学习的滥用、具备误导性的参数等。
其后几周深入科学研究领域,介绍了“发表偏倚(Publication bias)”、“掠夺性发表(Predatory publishing)”等概念,以及学科之内、学科之间互相批评的伦理。
第11周是关于假新闻的。内容包括假新闻的经济驱动、回音室效应、如何进行事实核查等等,都是新闻实验室经常谈到的内容。如果这门课开设在新闻学院,那么这方面的内容足够扩展成整整一门课了。不过因为这门课的重点放在了科学上,所以新闻方面的内容被压缩到了一节课。
最后一周讲的是如何驳斥狗屁。针对不同的受众,需要用到不同的策略。这方面的内容基本上就是传播学中的说服效果研究。
这门课程在2017年的春季开课,现在已经结束,老师也把课程的全部视频放到了YouTube上,感兴趣的同学打开下面的网址进行观看哦
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}