阅读:0
听报道
编译:籍缓、陆震
Kaggle的座头鲸识别挑战比赛在最近落下帷幕,全球共2131个团队参加了比赛。
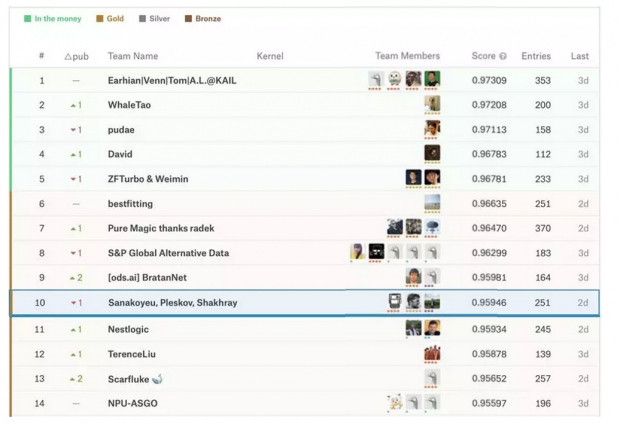
这是近期Kaggle上颇受欢迎的一次竞赛,常用的分类方法无法处理大量的无标注数据,只有对传统的方法进行创新,才能够获得高分。
下面文摘菌为大家介绍比赛中排名TOP10的团队如何完成比赛,以及其他几只团队的相关经验。
注:该团队由Vladislav Shakhray,Artsiom Sanakoyeu海德堡大学的博士组成,以及Kaggle Top-5 大神Pavel Pleskov。
本文作者Vladislav Shakhray,文摘菌对其编译如下。
比赛链接:
问题描述
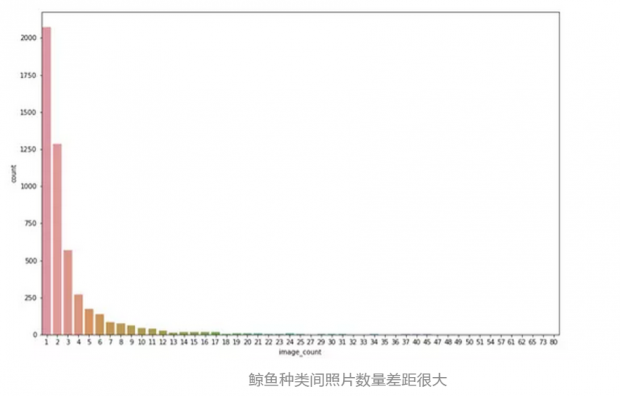
在比赛中,主要是构建算法来识别图像中的鲸鱼个体,而难点在于训练样本的严重不均衡以及存在近三分之一的无标注数据。

在超过2000个鲸鱼类别,只有一个训练样本,这使得常用的分类方法很难使用。更重要的是,无论鲸鱼是否是新的种类,这都是比赛的重要组成部分,结果证明这是非常重要的。
竞赛的衡量标准是MAP @ 5(平均精度为5),能够为每个测试图像提交最多5个预测。 我们在测试集上的最高成绩是0.959 MAP @ 5。
验证和初始设置
在本次比赛前几个月,同一比赛的另一个版本在Kaggle上举行,但是,正如竞赛发起人所指出的那样,现在的版本包含更多清洁的数据。我们决定以多种方式利用之前比赛的成果和数据:
1.使用之前竞争对手的数据,我们使用image hashing来收集超过2000个验证样本。 当我们稍后验证我们的成果时,这一方法非常重要。
2.我们从训练数据集中删除了new_whale类,因为它不在其元素之间共享任何逻辑图像特征。
3.有些图像根本没有对齐。 幸运的是,在之前一版kaggle比赛的成功解决方案中有一个公开可用的预训练边界框模型。我们用它来检测鲸鱼周围的精确边界框并相应地裁剪图像。
4.由于图像的颜色不同,所有数据在训练前都转换为灰色。
方法1:孪生神经网络Siamese Networks(Vladislav)
我们的第一个架构是一个具有众多分支架构和自定义损失的孪生神经网络(Siamese Networks),其中包括许多卷积和密集层。 我们使用的分支架构包括:
ResNet-18, ResNet-34, Resnet-50
SE-ResNeXt-50
Martin Piotte公开分享的类似ResNet的自定义分支
我们通过在每4个时期的分数矩阵上求解线性分配问题来使用显著阴性(hard-negative mining)和显著阳性挖掘(hard- positive mining)。 在矩阵中添加了一些随机化以简化训练过程。
使用渐进式学习(Progressive learning),分辨率策略为229x229 - > 384x384 - > 512x512。 也就是说,我们首先在229x229图像上训练我们的网络,几乎没有用正则化和更大的学习率。 在收敛之后,我们重置学习速率并增加正则化,从而再次对更高分辨率的图像(例如384×484)训练网络。
此外,由于数据的性质,使用了大量增强,包括随机亮度,高斯噪声,随机剪裁和随机模糊。
此外,我们采用智能翻转增强策略,极大地帮助创建了更多的训练数据。 具体地,对于属于相同的鲸鱼X,Y的每对训练图像,我们创建了另外一个训练对翻转(X),翻转(Y)。 另一方面,对于每对不同的鲸鱼,我们创建了另外三个例子:翻转(X),Y,Y,翻转(X)和翻转(X),翻转(Y)。

一个显示随机翻转策略不适用于一对相同鲸鱼照片的例子。 请注意当我们翻转图片时,两张图片的翻转效果不同,因为我们关心鲸鱼尾部的寄生藻的位置。
使用Adam优化器优化模型,初始学习率为1e-4,接近训练结束时减少5倍。 批量大小设置为64。
模型是用Keras编写的。在单个2080Ti上花费2-3天(取决于图像分辨率),训练模型大约400-600个周期。
使用ResNet-50性能最佳的单一模型得分为0.929 LB。
方法2:度量学习Metric Learning(Artsiom)
我们使用的另一种方法是使用保证金损失进行度量学习。 我们使用了许多ImageNet预训练的架构,其中包括:
ResNet-50, ResNet-101, ResNet-152
DenseNet-121, DenseNet-169
这些网络主要由448x448 - > 672x672策略逐步训练。
我们使用了Adam优化器,在100个训练周期后将学习率降低了10倍。 我们还为整个训练使用批量大小为96的训练方法。
由Sanakoyeu,Tschernezki等人开发的度量学习(metric learning)方法能够让成绩迅速提升。
度量学习在CVPR 2019上发布,它所做的是每个周期它将训练数据以及嵌入层分成簇。在训练组块和学习者之间建立双射之后,模型分别训练它们,同时累积分支网络的梯度。
代码及文章链接:
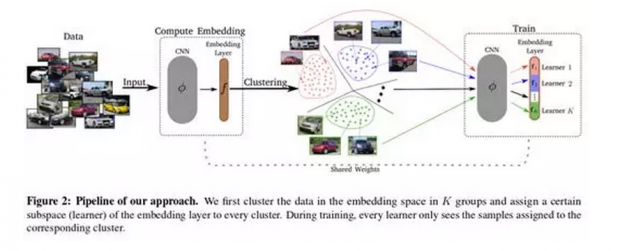
由于巨大的种类数量不平衡,我们使用了大量的增强,包括随机翻转,旋转,变焦,模糊,光照,对比度,饱和度变化。 之后,计算查询特征向量和列车库特征向量之间的点积,并且选择具有最高点积值的类作为TOP-1预测。 隐含地帮助类不平衡的另一个技巧是对属于相同鲸鱼id的火车图像的特征向量进行平均。
这些模型使用PyTorch实现,需要单个Titan Xp 2-4天(取决于图像分辨率)来训练。 值得一提的是,具有DenseNet-169架构表现最佳的单一模型得分为0.931LB。
方法3:特征分类(Artsiom)
当我和Artsiom联手时,我们做的第一件事就是使用从我们所有模型中提取并连接(应用PCA分析)的特征来训练分类模型。
分类的主要部分由两个密集的层组成,其间会删失信息。由于我们使用了预先计算的特征,因此模型训练得非常快。
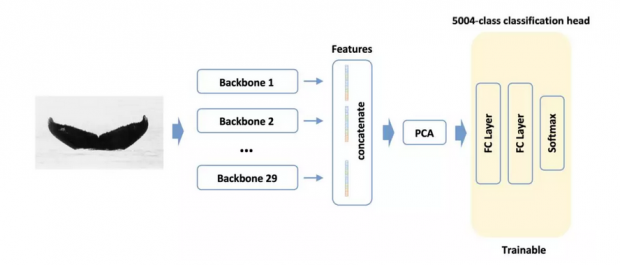
通过这种方法我们获得了0.924 LB,并让整个集合更富多样性。
方法4:新鲸鱼分类(Pavel)
本次比赛最复杂的部分之一是正确分类新鲸鱼(大约30%的图像属于新类别鲸鱼)。
解决这个问题的流行策略是使用一个简单的阈值。也就是说,如果给定的图像X属于某个已知类别鲸鱼的最大概率小于阈值,则将其归类为新鲸鱼。然而,我们认为可能有更好的方法来解决这个问题。
对于每个表现最佳的模型和集合,我们选取了TOP-4预测,按降序排序。然后,对于其他的每个模型,我们将他们的概率用于所选择的这4个类。目标是根据这些特征来预测鲸鱼是否属于新类别。
Pavel创建了一个非常强大的包含LogRegression,SVM,几个k-NN模型和LightGBM的混合模型。这个混合模型在交叉验证中给出了0.9655 的ROC-AUC值,并且将LB得分提高了2%。
综合
由我们的模型构建混合模型相当不容易。难度在于我的模型的输出是非标准化概率矩阵(从0到1),而Artsiom提供的输出矩阵由欧几里德距离组成(范围从0到无穷大)。
我们尝试了许多方法将Artsiom的矩阵转换为概率,其中包括:
1、类似tSNE的转换:
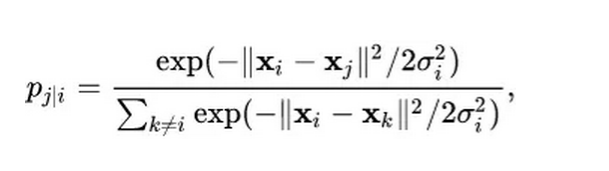
2、Softmax
3、通过应用函数 1 / (1 + distances)简单地反转范围
4、其他可以反转矩阵范围的函数
不幸的是,前两种方法根本不起作用,而使用大多数函数将范围剪切至[0,1]的结果大致相同。我们最终选择在验证集上具有最高mAP @ 5的函数。
令人惊讶的是,最好的是1 / (1 + log(1 + log(1 + distances)))。
其他团队使用的方法
大卫现在是Kaggle Grandmaster(等级为12),在Private LB上排名第四,并在Kaggle Discussions论坛上分享了他的解决方案。
他使用全分辨率图像并使用传统的关键点匹配技术,利用SIFT和ROOTSIFT。为了解决假阳性问题,大卫训练了一个U-Net从背景分割鲸鱼。有趣的是,他使用后期处理给只有一个训练样本的类别更多的机会跻身TOP-1预测。
我们也考虑过尝试基于SIFT的方法,但我们确信它肯定会比顶级神经网络表现得差。
在我看来,我们能从中学会的是,永远不应被深度学习的力量所蒙蔽,从而低估了传统方法的能力。
单纯分类
由Dmytro Mishkin,Anastasiia Mishchuk和Igor Krashenyi组成的Pure Magic thanks radek团队(第7名),追求将metric learning(triplet loss)和分类结合起来,正如Dmytro在他的文章中描述的那样。
在训练分类模型一段时间时,他们尝试使用Center Loss来减少过拟合,并在应用softmax之前进行temperature scaling。在使用的众多主干架构中,最好的是SE-ResNeXt-50,它能够达到0.955LB。
temperature scaling:
他们的解决方案比这更加多样化,我强烈建议你参考原文。
正如Ivan Sosin在文章中(他的团队BratanNet在本次比赛中排名第9)所述,他们使用了CosFace和ArcFace方法。下面是来自于原文:
Cosface和Arcface作为面部识别任务新近发现的SOTA脱颖而出。其主要思想是在余弦相似空间中将同类的例子相互拉近并分开不同的类别。通常是分类任务使用cosface或arcface,因此最终的损失函数是CrossEntropy
当使用像InceptionV3或SE-ResNeXt-50这样的较大主干网络时,他们注意到了过拟合,因而他们切换到较轻量的网络,如ResNet-34,BN-Inception和DenseNet-121。
文章链接:
该团队还使用了精心挑选的扩充和众多网络修正方法,如CoordConv和GapNet。
他们方法中特别有趣的是他们处理新类别鲸鱼的方式。下面是原文:
一开始我们就意识到必须对新鲸鱼做一些处理,以便将它们纳入训练中。简单的方法是给每个新鲸鱼分配一个1/5004的可能属于每一类别的概率。在加权采样方法的帮助下,它带来了一些提升。
但后来我们意识到可以使用softmax预测来自于训练集中的新鲸鱼。所以我们想到了distillation。我们选择distillation代替伪标签,因为新鲸鱼的标签应该与训练的标签不同,虽然它可能不是真的。
为了进一步提升模型性能,我们将带有伪标签的测试图片添加到训练集中。最终,我们的单一模型可以通过snapshot ensembling达到0.958。不幸的是,以这种方式训练的ensembling并没有在分数上有任何的提高。也许是因为伪标签和distillation造成的多样性减少。
最后的思考
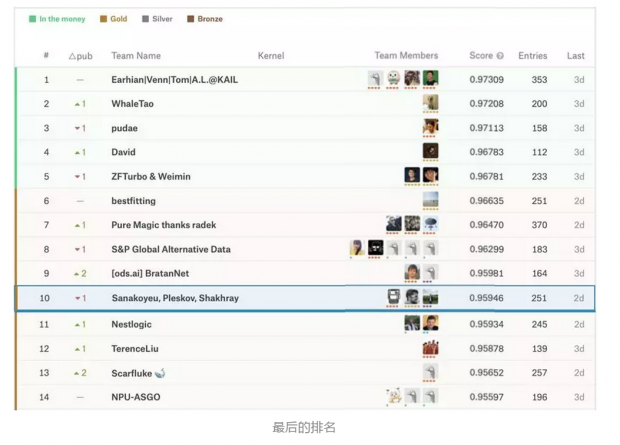
令人惊讶的是,尽管私人测试集占到全部测试集的近80%,但是最终结果几乎没有大的改变。我相信比赛的主办方已经提供了一个非常有趣的问题,以及经过很好地处理的数据。
这是我参加的第一场Kaggle比赛,毫无疑问,它表现出了Kaggle比赛的有趣,迷人,激励和教育性。我要祝贺由于这次比赛而成为Expert,Master和Grandmaster的人。我还要感谢社区提供的精彩讨论和支持。
最后,我要再一次特别感谢我的队友Artsiom Sanakoyeu和Pavel Pleskov,为我带来了一次难忘的Kaggle比赛经历。
相关报道:
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}