阅读:0
听报道
编译:小蒋、李可、狗小白、周素云
我们正处于AI创业热潮之中,机器学习专家的薪资水平水涨船高,投资者也乐于对AI初创公司慷慨解囊。AI的普及成为推动社会生产力标志,必将改变我们的生活。
但是,本文作者前谷歌工程师、的CTO Ric Szopa认为,AI从业者的技能正在贬值。他从一个选择题入手告诉我们,AI工具、数据集、资金投入以及行业+AI的优势正在一步步弱化单一的AI基础技术优势。
先来做一道选择题。
Alice和Bob是两位AI创业者, 他们的公司筹集了大致相同的资金,并在同一个市场上展开了激烈的竞争。
Alice把大部分钱花来雇佣最好的工程师,请来了一批在人工智能研究方面经验丰富的博士。
而Bob选择雇用资质一般但还算能干的工程师,并将省下来的钱用于获得更好的数据。
如果是你,你会给谁投资?
当然是Bob。
为什么呢?
从本质上讲,机器学习的原理是从数据中获取信息,并将其转化为模型权重。更好的模型使得这个过程更有效(时间或者整体质量方面),但如果假设模型训练相对都比较充分,更好的数据肯定会产生更好的结果。
为了说明这一点,让我们再进行一个快速而简单的测试。
假设我创建了两个性能不太一样的卷积网络。“更好”的模型的最后一个全连接层有128个神经元,而“稍微差一点”的只有64个。我在不同大小的MNIST数据集的子集上训练它们,并绘制模型在测试集上的准确率与训练样本数的折线图。
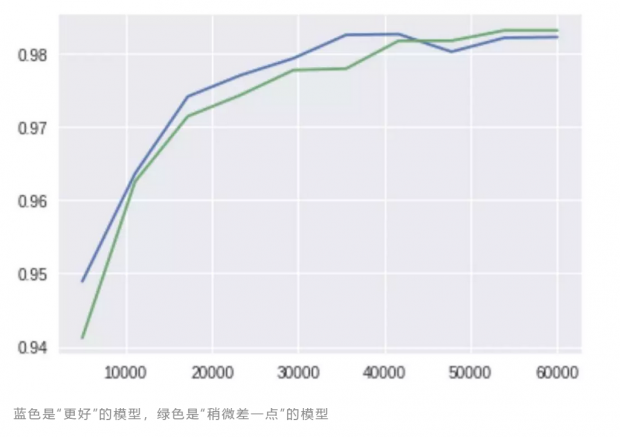
很显然,训练数据集大小具有积极影响(至少在模型开始过拟合和准确率达到稳定之前)。值得一提的是,在40000个样本上训练的“稍微差一点”模型的准确率比在30000个样本上训练的“更好”模型的准确率要高!
在我的小例子中,我们处理的是一个相对简单的问题,而且有一个比较全面的数据集。而在现实生活中,我们的条件并不是如此完美。在许多情况下,增加数据集经常会具有非常显著的效果。
事实上,Alice的工程师不仅仅是和Bob的工程师竞争。由于AI社区的开放文化及其对知识共享的重视,他们的竞争对手其实来自谷歌、Facebook、微软以及世界各地数千所大学的研究人员。
因此, 好的工程师虽然很重要的,但如果你是AI领域的话,数据的竞争优势会显得更为关键。
然而,更加重要的问题是,你如何才能保持自己的优势。
AI工具正越来越简单好用
2015年,当我还在谷歌工作,刚开始玩DistBelief,也就是后来我们所熟知的Tensorflow。当时这个工具太难用了,所以当时想让它在谷歌构建的系统之外运行完全是一个白日梦。
2016年末,我进行了一个概念验证的研究,在组织病理学图像中检测乳腺癌。当时我想使用迁移学习:采用谷歌当时最好的图像分类架构Inception,并在我的癌症数据上重新训练。我可以使用谷歌提供的一个经过预训练的初始权重,改变顶层结构来匹配我正在做的工作。
在TensorFlow上经过长时间的反复尝试,我终于找到了操作不同层的方法,让它基本上运作起来。这需要很大的毅力去阅读TensorFlow的资料。不过至少我不必太担心依赖关系,因为TensorFlow贴心地准备了Docker镜像。
在2018年初,多亏了Keras(基于TensorFlow的一个框架),只需几行Python代码就能完成这个项目,而且使用它不需要你对自己正在做的事情有深入理解。但它仍然有个痛点:超参数调优。
如果你有一个深度学习模型,可以调节多个参数,如层数和大小等。在我写这些文字的时候(2019年初),谷歌和亚马逊提供了自动模型调优服务(Cloud AutoML,SageMaker)。
我预测手动调优迟早会灭绝,工程师们也会从这项繁琐的工作中解脱了。
总的趋势是,将困难的事变得容易,你无需深入理解就能实现更多的东西。过去的那些伟大工程现在听起来相当一般,所以我们不应该期望我们现在的成就在将来有多好。
听起来很欢欣鼓舞是不是,但是,对于那些在AI技术上投入巨资的公司和个人来说,这可以是个坏消息。目前来说,掌握某些AI技术还算是企业的竞争优势,因为一个称职的机器学习工程师需要花费大量的时间阅读论文,并需要扎实的数学背景。
但是,随着工具的改进,情况将不再如此。读论文更多会转向读工具教程。如果你没有很快意识到你该关注的重点,一个带了数据更完备的实习生团队就可能会抢走你的饭碗。
想长期保持竞争优势?难上加难!
让我们再回到文章开头的例子。凭借出色的数据集,Bob成功地与Alice展开竞争,推出了自己的产品,并稳步增加了市场份额。他也慢慢可以开始雇佣更好的工程师,因为坊间传言他的公司是一个好去处。
但这时候,又出现了一个Chuck,虽然入局晚,但他比Bob更有钱。
在构建数据集时,钱至关重要。但通过砸钱来加快工程项目进度非常困难。事实上,使用太多新人可能会减缓进度,但构建数据集就不同了。数据集需要大量人工操作,而你可以通过雇用更多人手来搞定它。另一种可能是有人拥有数据,那么你所要做的就是支付数据使用费。
无论如何,钱能让数据集来得更快。
但是问题来了,为什么Chuck可以筹到比Bob更多的钱?
当创始人提出一轮融资时,他们会努力平衡两个可能相互矛盾的目标。他们需要筹集足够的资金在市场上竞争,但也不能太多,因为这会导致股权过度稀释。创始团队必须在创业公司中保持足够的股份,以免失去创业的动力。
另一方面,投资者希望投资具有巨大上升潜力的创意,但他们必须控制风险。随着预期风险的增加,他们会为支付的每一美元要求更大比例的股份。
当Bob筹集资金时,“人工智能确实对产品有所帮助”不过只是一个信念。无论他作为创始人多优秀,她的团队有多好,但有可能他试图解决的问题根本就难如登天。Chuck的情况非常不同。他知道他面临的问题完全可以解决!
在这种情况下,Bob的应对方法很可能是提出另一轮融资,以便处于有利位置,因为他(暂时)仍然在竞争中领先。但是,如果Chuck可以通过战略合作关系稳固获取数据呢?比如举个癌症诊断初创公司的例子,Chuck可能利用他在一家重要医疗机构的内部职位,与该机构达成一份内部协议。这时候, Bob很可能无法抗衡。

AI的杠杆效应
对业务进行分类的一种方法是,它是直接增加价值,还是为某些其他价值来源提供杠杆效应。以一家电子商务公司为例,增加价值就像创造了新的产品线,建立新的分销渠道则是一个杠杆,削减成本也是杠杆。
杠杆可能比直接施力更有效。但是,杠杆仅在与直接价值来源耦合时才起作用。一个微小的数字,翻了两倍,三倍,还是很小。如果你没有可出售的部件,开辟新的分销渠道也只是浪费时间。
在这种情况下我们应该如何看待AI?有很多公司试图将AI作为他们的直接产品(用于图像识别的API等),对一个AI专家,这可能很有吸引力。
然而,这常并不是一个好的选择。首先,你是在Google和亚马逊等这些大公司竞争。其次,开发真正有用的通用AI产品非常困难。例如,我一直想使用Google的Vision API。不幸的是,我们从未遇到过客户需求与产品充分匹配的情况。总是有各种各样要么开发不够要么开发过度的情况。
更好的选择是将AI视为杠杆。
你可以采用现有的,有效的商业模式,通过AI增强它。例如,如果生产流程依靠人类的认知劳动,那么将其自动化可能会为毛利率带来显著提升。这里我能想到的例子有:心电图分析,工业检查,卫星图像分析。同样令人兴奋的是,因为AI属于辅助后端,仍然可以利用非AI业务来保持公司的竞争优势。
结论
AI是一项真正的变革性技术。但是,以此为基础创业是一件棘手的事情。你不应该完全依赖于AI技能,因为市场趋势就是技术会贬值。
构建AI模型可能非常有趣,但真正重要的是拥有比竞争对手更好的数据。
保持竞争优势很难,特别是遇到比你资金更充足的竞争对手,这种情况在你的AI创业进行时很可能发生。你的目标应该是创建一个可扩展的数据收集过程,而这个过程很难被竞争对手复现。
AI非常适合颠覆依赖低附加值、劳动重复性的行业,因为它使该工作自动化成为可能。
相关报道:
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}