阅读:0
听报道
作者:Christopher Dossman
编译:Vicky、云舟
本周关键词:基于AI的X光、机器人抱抱、量化BERT模型
本周最佳学术研究
一种用于自动驾驶和映射任务的新数据
一组研究人员公开了一个覆盖350多公里,时间超过10个小时的汽车驾驶记录。这些记录在任何其他公共数据集中都是不存在的。
该数据集涵盖了城市中心、郊区、高速公路、农村等多种环境,主要是在捷克共和国的布尔诺以及周边地区记录的。它包含来自高质量传感器的数据——四个WUXGA摄像机、两个3D激光雷达、惯性测量单元、红外摄像机和厘米级RTK GNSS接收器等。
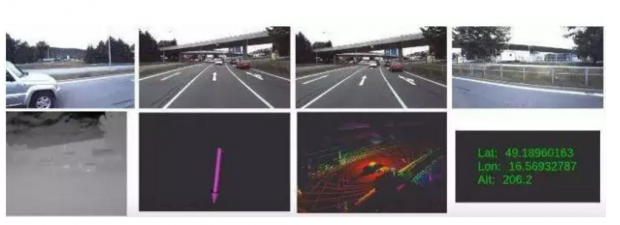
这组数据的一个特别之处是使用了一个热成像相机,可以在恶劣的天气甚至是电闪雷鸣的条件下定位。此外,所有的数据都有精确的时间戳,精度在毫秒以下,可以被更广泛地应用。
共享数据可以让更多的研究人员参与到某一特定领域的研究进程中,通过使用新的数据和新鲜的想法来研究它,科研世界中的每一个研究者都会受益。
Brno数据集的原始格式非常易于阅读,它还带有一个能够将数据转换为ROS包的脚本,这些优势使得它在推动自主驾驶发展的研究上具有重要的潜力。该研究也为基础数据处理提供了工具,未来研究人员有望利用雷达、里程计和神经网络数据预处理传感器对数据进行更新。
数据集:
原文:
BERT模型的新型量化方法
为了最小化BERT模型的性能退化,UCBerkeley的研究人员提出了一种有效量化Q-BERT的方案。
这项工作在广泛的二阶信息逐层解析(Hessian information)的指导下,BERT上应用混合精度量化。研究人员还提出了一种新的量化方案,称为逐组量化,它可以不增加硬件复杂度的情况下减少精度退化。
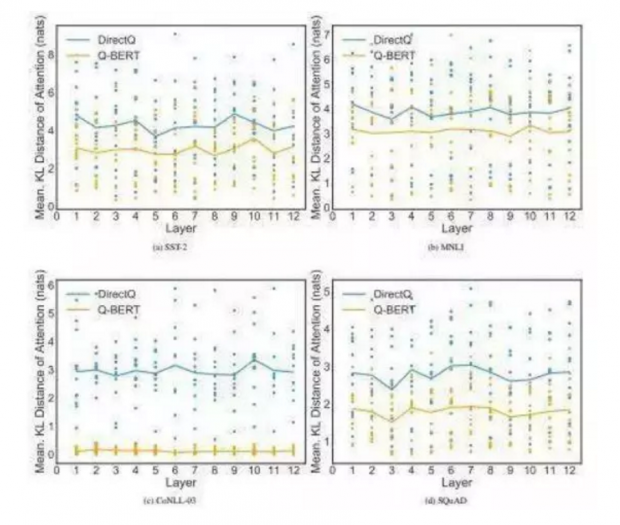
研究还探讨了阻碍BERT量化的因素,包括不同的量化方案和模块(如嵌入、自关注和全连接层)如何影响NLP性能和模型压缩比之间的平衡。
研究人员称:“据我们所知,这是量化BERT以可接受的性能损失下实现超低比特的第一项工作。”
Q-BERT在情感分类、自然语言处理、对象识别、机器阅读理解等四个下游任务中,实现了13倍的权重压缩比、4倍的激活量和4倍的嵌入量,而准确率的损失还不超过2.3%。
推理效率已经成为ML的一个重要问题,量化是通过减少表示数据的比特数来提高推理效率的。这样的研究有很大的潜力,因为它们可以帮助类似智能手机这样的算力受限设备实现更鲁棒的模型。
原文:
Google AI:脉冲神经网络中的时间编码
在一个称之为Ihmehimmeli的项目中,谷歌研究人员展示了人工脉冲神经网络如何利用多种架构和学习设置来开发时间动态。他们提出了一个脉冲神经模型,该模型根据单个脉冲的相对时间来编码信息。
“ImiMeMeli”一词借用自芬兰语,意思是一个复杂的工具或元素。研究人员解释说,这个名字巧妙地描述了他们的目标,即开发具有时间编码信息的复杂递归神经网络结构。
一般来说,人工网络缺乏像大脑那样利用时间对信息进行编码的能力。在这一模型中,研究人员使用带有时间编码方案的人工脉冲网络,其中的特殊信息,例如更大的声音或更亮的颜色,会导致更早的神经元脉冲。
在信息处理的层次结构中,获胜的神经元是最先出现脉冲的神经元。这样的编码可以自然地实现一种分类方案,其中输入特征在它们对应的输入神经元的脉冲时间中被编码,而输出特征则由最早达到脉冲的输出神经元编码。
脉冲网络受到了生物神经结构的启发,通过研究脉冲网络中的时间编码,有可能创造出一种更节能、更复杂的神经结构发展模块。
这一模型以多种方式对现有的脉冲网络模型进行了显著改进,并且可以解决使用时间编码的标准机器学习基准问题。
此外,研究人员还证明了使用一种生物学上α突触功能的合理性。Alpha函数包括一个衰减成分,它允许在神经元没有被刺激时忘记较早的输入,这有助于修正潜在的虚假脉冲。
这项工作为学术界提供了一个时间编码原型,以创建面向递归和基于状态的神经计算架构的基础。
原文:
实现可扩展的多域会话代理
虚拟助手在提高工作效率和协作方面显示出了无穷的潜力。因此,它们的研究与开发引起了很多人的兴趣。但对于人工智能领域的新兴研究来说,总有一个无法回避的挑战——缺乏用于多个域的足够数据。
为了应对这一挑战,研究人员引入了一组新的模式引导对话(Schema-Guided Dialogue/SGD)数据集,其中包含了跨16域的超过16k的多域对话数据。
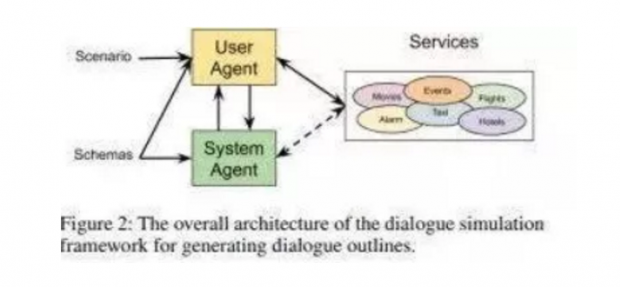
这一数据集在规模上超过了现有的面向任务的对话语料库,同时也针对性地解决了与构建大型虚拟助理相关联的挑战。
随着学术界和业界都在努力改进会话代理,不同领域的高质量数据至关重要。
据这项工作的研究人员称,这是目前最大的面向公共任务的对话语料库。所提出的单一对话系统能够轻松支持大量服务,并有助于在不需要额外训练数据的情况下促进新服务的简单集成。
这项工作有可能进一步推动针对虚拟助理的研究,并帮助机器学习社区实现更强大的系统。具体而言,数据集可以用作意图预测、语义填充、状态跟踪、语言生成以及大规模虚拟助理中其他任务的有效测试平台。
参考代码:
原文:
情感分类中的文本长度自适应
尽管在跨域/语言任务中,无监督迁移学习已经得到了很好的研究,但是跨长度迁移(CLT)仍然没有得到足够的探索。其中一个原因是长度差在分类中的可转移性很小。
在本篇文章中,研究者表明,这并不是因为短/长文本在语境丰富度和单词强度上存在差异。他们从不同领域和语言设计了新的基准数据集,并表示来自类似任务的现有模型无法应对跨文本长度迁移的独特挑战。
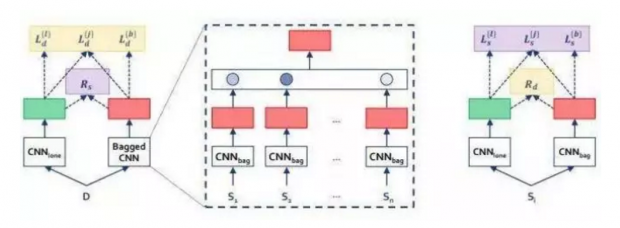
他们还引入了一个称之为BaggedCNN的强基线模型,该模型将长文本视为包含短文本的包,并推荐了一个名为长度迁移网络(LeTraNets)的最新CLT网络:该CLT网络针对短文本和长文本提供了一个使用多种训练机制的双向编码系统。在评估中,BaggedCNN模型性能比传统模型差,而LeTraNets则击败了所有模型。
文本可以作为一种极其丰富的信息源,这解释了现代企业转向文本分类以增强决策能力和自动化流程的原因。然而,由于其非结构化的性质,从文本中提取见解是具有挑战性且耗时的。
文本分类器可用来组织、构造和分类几乎任意东西。所提出的LeTraNets包括一个段级本文编码器CNNbag用来捕获段级文本特征。
LeTraNets的实现:
原文:
其他爆款论文
基于说话者识别的实时文本显示效果评估:
学习解决服务机器人的任务:
新的自动驾驶数据集,它是Pioneering KITTI数据集的10倍,是nuScenes数据集的3倍:
一组新的音乐源分离研究开放式数据集,其中包括乐器混合音和相应成分的高质量渲染:
帮助类人型机器人学会预测人类爱的抱抱并对其作出反应:
一组自动驾驶代理和映射任务的新数据:
AI头条
华为宣布开发开源架构计划,以满足日益增长的计算能力和人工智能要求:
还有人工智能驱动的X光?
从现在起,你可以从任意手机呼叫Google Assistant了:
你有没有想过,人工智能的进步会让社会变得更糟:

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}