阅读:0
听报道
本周关键词:目光追踪、音频信号分类、GPU
本周最佳学术研究
大规模目光追踪数据集与鲁棒的3D目光估计
如何收集精确且高度变化的目光数据是一项艰巨地任务。在本文中,研究人员提出了一种有助于处理任务并缩小现有性能差距的方法。首先,他们描述了一种在任意环境中有效收集带注释的3D目光数据的方法。然后,他们使用该方法获得了最大的3D目光数据集并命名为Gaze360。

该数据集捕获了室内和室外条件下238个对象的视频内容,并仔细评估误差和特征。在确定最终模型之前,研究人利用数据集训练了各种3D目光估计模型,该模型独特地采用了多帧输入,并利用弹球损失进行误差分位数回归分析,以此提供目光不确定性的估计。
利用交叉数据集模型性能的比较方法,研究人员对Gaze360与常规数据集进行了评估。研究人员进一步研究证明了新模型可以应用于实际用例,包括估算顾客在超市中的关注点等等。
这项工作介绍的方法可以大规模地收集带注释的目光数据,并使用它来生成一个庞大且多样化的数据集,以用于图像和视频3D注视的深度学习。通过与三个现有3D目光数据集的交叉数据集性能比较,以及通过将应用程序应用于YouTube视频中不受约束的可见图像,研究人员证明了该方法的价值。
研究人员希望这个模型和数据集在各个领域中的应用将有助于更好地利用目光追踪技术,提高对基于视觉的人类行为理解。
数据集和模型:
原文:
为端到端自动语音翻译开发间接训练数据
Facebook和约翰霍普金斯大学的研究人员通过数据增强,开发了几种利用自动语音翻译(ASR)和机器翻译(MT)数据,来辅助端到端系统的技术。研究人员研究了几种旨在弥合端到端模型和级联模型之间差距的技术。他们证明了在不局限于仅训练AST数据的情况下,级联模型非常有竞争力。
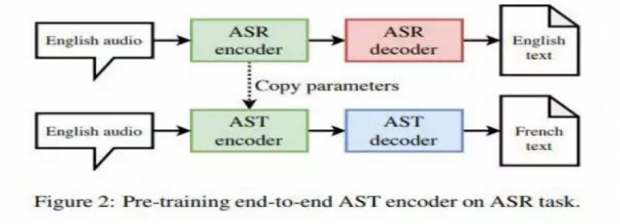
通过数据增强,预训练,微调和体系结构选择,研究人员训练了端到端模型,与级联方法相比,前者竞争优势明显。他们的方法将端到端和强级联模型之间的性能差距在En–Fr Librispeech AST数据上从8.2 BLEU减少到了1.4 BLEU,在En–Ro MuST-C语料上从6.7 BLEU减少到3.7 BLEU.
在日益数字化的世界中,有效的语音翻译有了更多的应用。难怪研究人员和开发人员正在越来越多地致力于实现强大的语音技术,发展更快地文本数据翻译。更好的语音翻译具有巨大的潜在用途,包括帮助消除当前的全球翻译挑战等等。但是,实现他们的前提是拥有高质量和足够多的数据。
通过这项工作,研究人员能够评估AST的几种数据增强和预训练方法。此外,他们的工作还提供了关于如何利用此类数据的建议,增强了语音翻译的最新水平并有助于提高效率和生产力。
原文:
音频信号分类的深层神经网络
这项新的研究通过使用先前提出的分层相关传播(LRP)技术,研究了音频域中神经网络的可解释性。在本文中,研究人员介绍了一个新的英语口语音频数据集并将其用于数字和说话者性别的分类任务,他们应用LRP来识别两个用波形或频谱图处理数据的神经网络架构的相关特征。
根据从LRP获得的相关性分数,研究人员获得了有关神经网络特征选择的假设,并随后通过对输入数据的系统操作进行检验。评估结果表明,网络高度依赖于LRP标记为重要的特征。
对于许多机器学习应用程序而言,可解释的模型决策变得越来越重要。但是,当前的研究主要集中在解释图像分类器上。
本文提供了英语口语数字的数据集作为原始波形记录,激发了与解释音频分类模型有关的研究工作。这项工作清楚地证明了分层相关传播是一种用于解释音频分类神经网络的合适方法。
原文:
对抗性扰动交叉表示的可传递性:从频谱图到音频波形
本文具体演示了基于频谱图的音频分类器如何容易受到对抗性攻击,以及此类向音频波形的攻击的可传递性。
这类攻击会产生人类视觉不可见的扰动频谱图。通过评估一个西方音乐的数据集,结果显示在合法示例中,二维卷积神经网络(2D CNN)的平均准确率高达81.87%,而在对抗示例中,这个指标下降至12.09%.此外,从对抗频谱图重建的音频信号会产生听觉上类似合法音频的音频波形。
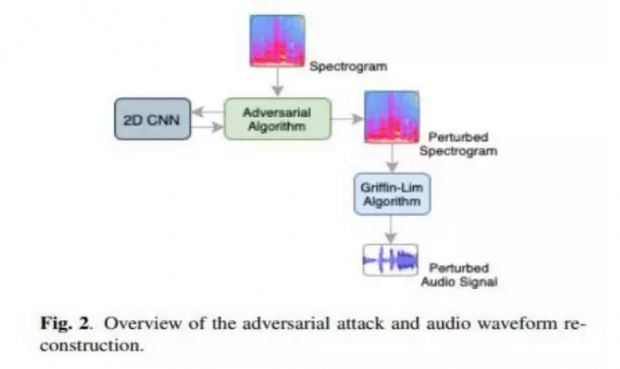
经学者证明,对音频信号二维表示的对抗性攻击在频谱图图像上是看不见的,并且它们可以轻松地被转移到音频波形上而丝毫不被察觉。因此,没有人类可以听见或看见的检测对抗示例的方法。
使用相位信息从短时傅立叶变换(STFT)频谱图重建的音频信号有非常高的信噪比(SNR),从此类频谱图重建的对抗音频的信噪比也大于20分贝。此研究得出结论,在抵抗对抗攻击的鲁棒性方面,二维表示可能不是最安全的。
原文:
用于批量在线和离线语音识别的GPU加速Viterbi精确格栅解码器
在本文中,研究人员介绍了一种优化的加权式有限状态传感器(WFST)解码器,该解码器能够使用图形处理单元(GPU)进行音频的在线流处理和离线批处理。
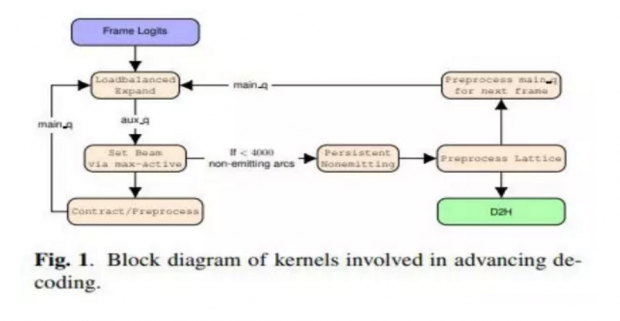
该解码器无需语言或声学模型修改,可作为现有解码器的直接替代品。特殊的设计使它具有灵活性、可同时支持多个音频流的在线识别和格栅生成。有限的内存利用率可确保大型语言模型和共存声学模型在GPU内存上具有足够的空间。该算法可以从在低功耗嵌入式GPU上运行的小型GPU扩展到在单个服务器上运行的多个数据中心级GPU。
本文提出的解码器有效地利用了内存、输入和输出带宽,并且使用了一种旨在优化并行度的新Viterbi实现。在得到等价结果的同时,这种新的实现方式预计可达到单核CPU解码的240倍速;与当前最先进的GPU解码器相比,解码速度可提高40倍。
该解码器与声学模型(AM)和语言模型(LM)无关,因此无需更改即可使用Kaldi工具包中训练的现有模型进行推断研究。
与基于CPU的基线多线程算法和当前最先进的GPU实现相比,研究人员运行这个解码器并行处理多种话语、优化内存管理和进行额外计算以减少同步,能够始终如一地获得更高数量级的加速。这些工作可以直接用于嵌入式平台,无需任何模型更改。
原文:
其他爆款论文
一种用于语音处理的深度特征提取器:
人员再识别,新的双重部分对齐表示方案解决非人部分的错位问题:
可解释的人工智能(XAI):概念、分类法、机遇和挑战:
Pytorch中用于人员再识别的深度学习库:
更快更安全的规则插入学习框架,用于整合高级规则和深度Q学习:
数据集
用于训练和评估模型的大规模、高实用性数据集:
用于联合学习的真实世界图像数据集:
#/
用于分类和增稠路面问题的新基准数据集:
最大的公共美国手语(ASL)数据集,用于促进单词级符号识别研究:
AI大事件
Netflix最近开放了Polynote的资源,Polynote是一个很酷的机器学习和数据科学工作流程工具:
计算机嗅觉?谷歌研究员正在训练机器如何去感知味道:
在Facebook支持的Deepfake检测竞赛中,AWS为研究员提供了计算能力。亚马逊以100万美元的云信用额度支持微软和Facebook:
AI现在可以在瘫痪患者在想象中写字时阅读他们的想法:

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}