阅读:0
听报道
文 | 曹培信
人们通常会派出最强大的选手和场景训练人工智能,但是,智能体如何应对训练中故意碰瓷儿的“弱”对手呢?
来看看下边的两个场景:两个AI智能体正在“训练场“进行一场激烈的足球赛,一个守门、一个射门。当守门员忽然自己摔倒,攻方没有选择乘胜追击,也忽然不知所措了起来。
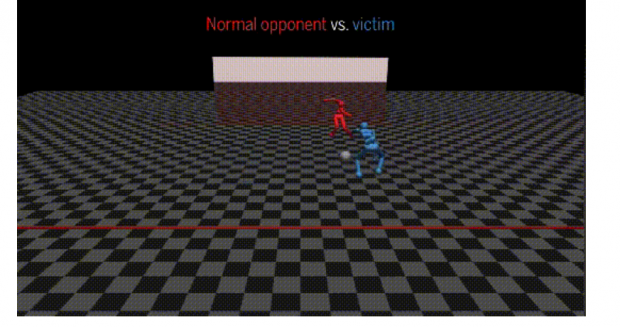
在相扑的规则下也一样,当其中一个队员开始不按套路出牌时,另一个对手也乱作一团,双方立刻开始毫无规则扭打在一起。
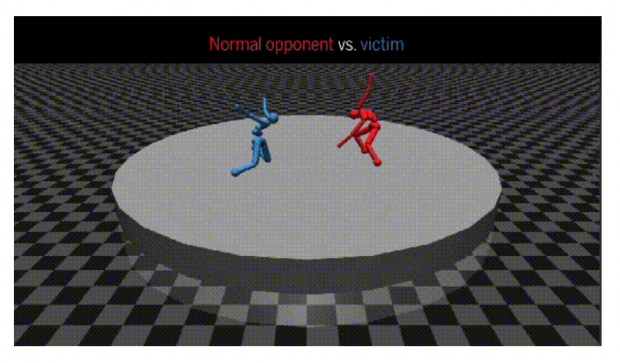
这样“人工智障”的场景可不是随意配置的游戏,而是一项对AI对抗训练的研究。
我们知道,通常情况下,智能体都是通过相互对抗来训练的,无论是下围棋的阿法狗还是玩星际争霸的AlphaStar,都是通过海量的对局来训练自己的模型,从而探索出获胜之道。
但是试想一下,如果给阿法狗的训练数据都是围棋小白乱下的对局,给AlphaStar提供的是小学生局,结果会是如何?
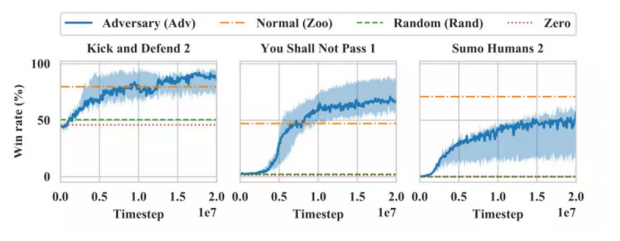
近期,来自伯克利的研究人员就进行了这样的实验。红色机器人与已经是专家级别的蓝色机器人进行对抗训练,红色机器人采取一定的对抗策略攻击蓝色机器人进行的深度学习。这项研究的论文作者也在NIPS大会上对该研究进行了展示。

论文链接:
在实验中,红色机器人为了不让蓝色机器人继续从对抗中学习,没有按照应有的方式玩游戏,而是开始“乱舞”起来,结果,蓝色机器人开始玩得很糟糕,像喝醉了的海盗一样来回摇晃,输掉的游戏数量是正常情况下的两倍。
研究发现,在采取对抗性政策的对局中,获胜不是努力成为一般意义上的强者,而是采取迷惑对手的行动。研究人员通过对对手行为的定性观察来验证这一点,并发现当被欺骗的AI在对对手视而不见时,其表现会有所改善。
我们都知道,让人工智能变得更聪明的一个方法是让它从环境中学习,例如,未来的自动驾驶可能比人类更善于识别街道标志和避开行人,因为它们可以通过海量的视频获得更多的经验。
但是如果有人利用这一方式进行研究中所示的“对抗性攻击” ——通过巧妙而精确地修改图像,那么你就可以愚弄人工智能,让它对图像产生错误的理解。例如,在一个停车标志上贴上几个贴纸可能被视为限速标志,同时这项新的研究也表明,人工智能不仅会被愚弄,看到不该看到的东西,还会以不该看到的方式行事。
这给基于深度学习的人工智能应用敲响了一个警钟,这种对抗性的攻击可能会给自动驾驶、金融交易或产品推荐系统带来现实问题。
论文指出,在这些安全关键型的系统中,像这样的攻击最受关注,标准做法是验证模型,然后冻结它,以确保部署的模型不会因再训练而产生任何新问题。
因此,这项研究中的攻击行为也真实地反映了在现实环境中,例如在自动驾驶车辆中看到的深度学习训练策略,此外,即使被攻击目标使用持续学习,也会有针对固定攻击目标进行训练的策略,攻击者可以对目标使用模拟学习来生成攻击模型。
或者,在自动驾驶车辆,攻击者可以通过购买系统的副本并定期在工厂重置它,一旦针对目标训练出了敌对策略,攻击者就可以将此策略传输到目标,并利用它直到攻击成功为止。
研究也对今后的工作提出了一些方向:深度学习策略容易受到攻击,这突出了有效防御的必要性,因此在系统激活时可以使用密度模型检测到可能的对抗性攻击,在这种情况下,还可以及时退回到保守策略。
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}