阅读:0
听报道
文 | 郑磊 陈瑶
文章经授权转载自复旦DMG
自武汉新型冠状病毒感染的肺炎疫情暴发以来,各级各地政府部门已通过多种官方渠道发布了大量疫情信息。然而在大数据时代,公众的信息需求已发生了变化,面对疫情,他们想知道的不仅仅是防控工作动态、自我防护知识、相关政策文件等信息,他们还想知道有关疫情的一些具体的、量化的数据。
首先,公众希望获知一个地方总体概况的统计数据:比如各个省市或区县今天累计有多少疑似、确诊、危重、出院或死亡病例?今天又新增或减少了多少?疑似病例中有多少人被排除了?密切接触者中又有多少人被解除了观察?
此外,公众还想了解一些有关病人个体的数据,比如这些病人分别从哪里来?去过哪里?哪天发病的?在哪家医院就诊?有什么病症?目前情况如何?
各地方的卫生健康委员会是权威的疫情数据发布部门,所以,我们选取了四个直辖市的卫健委官网,看看这几个特大型城市面对疫情时发布了哪些数据?具体包括哪些数据项(字段)?这些数据是以什么方式发布的?以什么形式呈现的?我们采集的官网数据的截止时间为2020年1月29日中午12时。
怎样在各直辖市的卫健委官网上找到疫情数据?
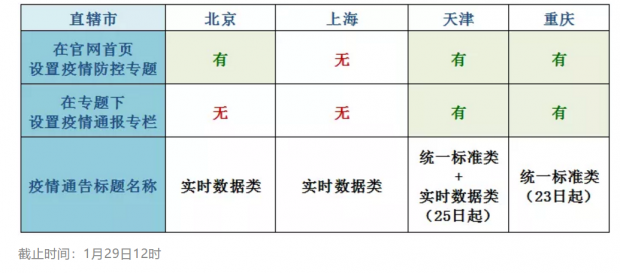
我们发现,北京、天津和重庆均在卫健委官网首页显著位置开通了与疫情防控相关的专题栏目,对疫情发展、防控工作、新闻报道、防护知识等内容进行专题发布,便于公众发现和访问(见下图)。
重庆市卫生健康委员会官方网站首页(1月28日截图)
然而,上海尚未在首页上开通与“疫情防控”相关的专题栏目,疫情通报信息出现在常规的“新闻发布”栏目下(见下图)。
上海市卫生健康委员会官方网站首页(1月28日截图)
在天津和重庆的疫情专题下,还专门开设了“疫情通报”专栏(见下图),集中发布疫情数据,便于用户查找。
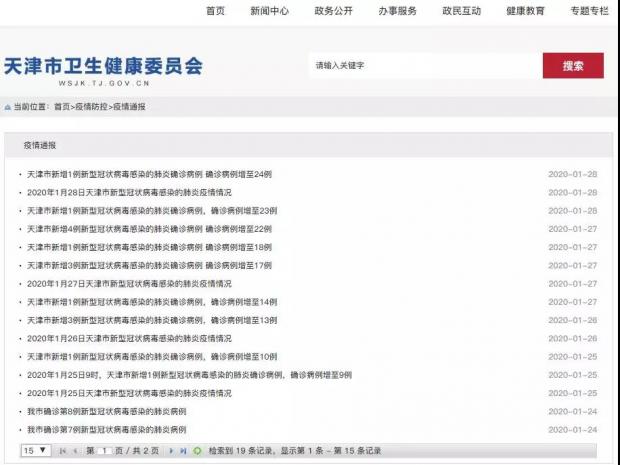
天津市卫生健康委员会官网的疫情通报专栏(1月28日网站截图)
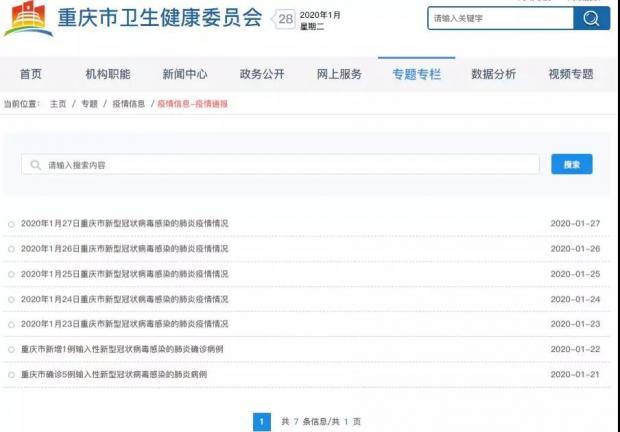
重庆市卫生健康委员会官网的疫情信息专栏(1月28日截图)
但北京和上海并未开通专栏,而是将疫情数据与各类防控工作动态、通告说明、新闻报道等信息混杂在一起进行发布(见下图),不便于公众快速搜寻。
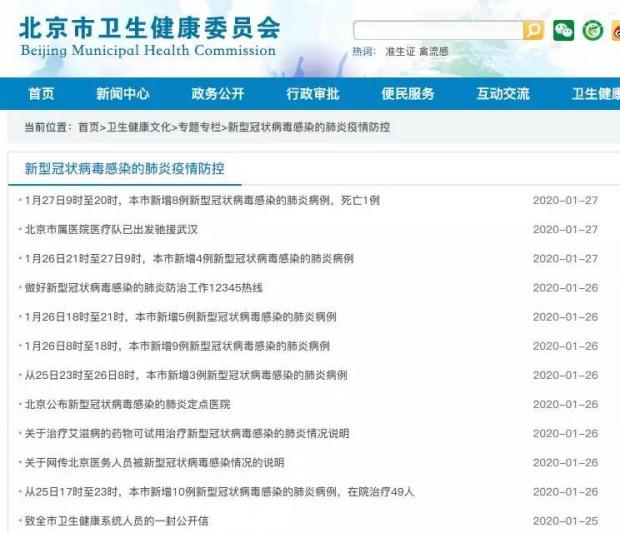
北京市卫生健康委员会官网的疫情防控专栏(1月28日截图)
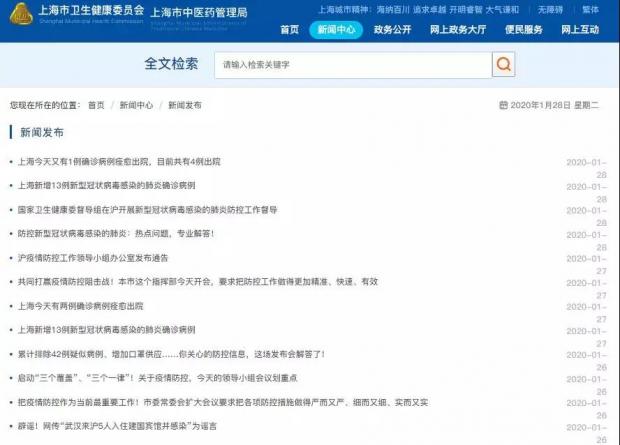
上海市卫生健康委员会官网的新闻发布板块(1月28日截图)
疫情通告文件的名称也会影响查找疫情数据的便捷程度。我们发现目前各个直辖市疫情通告的标题并没有统一规范,大致有两种类型:
一类是每日统一以“疫情情况”的标准化标题进行通报,例如“2020年1月29日重庆市新型冠状病毒感染的肺炎疫情情况”,我们暂且把这种类型称为“统一标准类”。
另一类是实时数据类,以在标题中出现“确诊病例”、“累计病例”、死亡病例”、“出院病例”数据的方式来实时通报疫情情况,例如北京卫健委发布的“1月28日12时至29日12时,本市新增11例新型冠状病毒感染的肺炎病例”,我们暂且把这种类型称为“实时数据类”。
一般来说,统一标准类标题的优势是规范性更强,也更便于搜索查找;劣势是标题自身包含的信息量不大,最新数据没有直观地显示在标题中,需要公众点开内容后才能看见。实时数据类的优势是能在标题中呈现关键数据,灵活动态性强;劣势则是缺乏统一规范,在通报发布数量较大的情况下不利于公众快速搜寻。
建议可结合两种标题的优势来取名,例如:“2020年1月29日XX时XX市XX疫情情况:本市新增11例病例”,这样既可以统一标准,便于查找搜索,又能在标题中直接展示动态数据,直观灵活。
目前,天津和重庆两市在进行疫情通报初期均采用实时数据类标题。之后,重庆市从1月23日起改为采用统一标准类标题,天津市从1月25日起兼用两类标题分别进行通报。北京和上海则一直采用实时数据类标题进行通报,但上海的标题中没有包含数据的统计时间,不便于按时间查找。
四个直辖市卫健委在官网设置疫情防控专题、开设疫情通报专栏,以及疫情通告标题的命名情况如下图所示:
哪个直辖市发布的疫情数据最容易被看懂和利用?
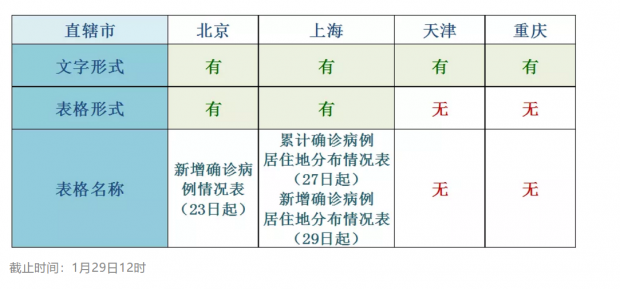
各直辖市均在官网上提供了文字形式的疫情情况通报,例如重庆通过文字对疫情数据一一进行了罗列说明(见下图)。虽然展示的疫情数据足够详细,但这些数据是以夹杂在文字中的形式出现的,不够清晰直观,不便于普通读者阅读和理解,也不利于专业人员进行分析利用。如果想对这些数据进行一些分析,需要先将数据从这些文字中提取和整理出来,做成数据表。因此,这种将数字夹杂在文字中发布的方式还未能真正进入数据时代,缺乏数据思维。

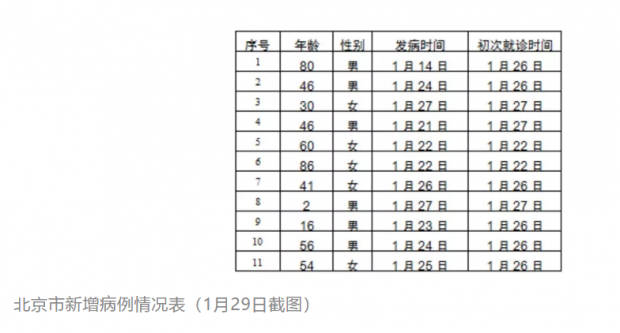
目前,只有北京和上海在文字之外,还使用了结构化表格的形式来发布疫情数据。其中,北京从1月23日起每天持续发布新增病例情况表,上海从1月27日起发布累计确诊病例居住地分布情况表,并从1月29日起发布了新增确诊病例居住地分布情况表(见下图)。
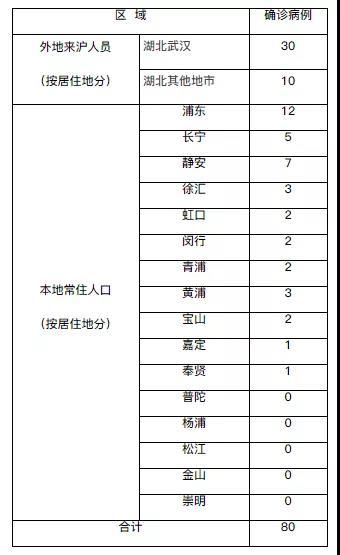
上海市累计确诊病例居住地分布情况表(1月29日截图)
在详细的文字描述之外,再通过表格的形式来呈现数据,不仅仅是为了便于普通读者解读数据,也是为了易于专业人员进行分析利用。
传统的信息公开主要以非结构化的、文本的形式提供,便于公众阅读,而在大数据时代,提供结构化的、可机读的数据,有利于用户对数据进行分析利用。而这正是数据开放和信息公开的一个重要区别。政府信息公开的主要目标是保障公众的知情权,提高政府透明度,而政府数据开放则不仅要让社会知情,还要让社会能对政府数据进行再次开发利用,创造社会和经济价值。
美中不足的是,目前北京和上海以表格形式发布的疫情数据还是以图片格式提供的。图片格式便于阅读,不易被修改,但不易被机器读取,不利于专业人员对数据进行分析利用。如果这些表格能以机器可读取的Excel或csv等格式提供的话,就能更方便被直接拿来分析利用了。
四个直辖市卫健委在官网发布的疫情数据的形式和表格名称如下图所示:
哪个直辖市发布的有关疫情整体情况的数据最多、最全?
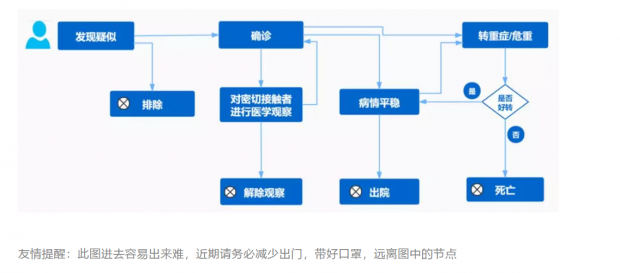
我们根据各直辖市发布的疫情数据,大致将疫情的发展和防治过程分为以下环节:有些病人经历了从疑似、确诊、病情平稳到出院的过程,也有病人不幸转为重症、危重直至死亡。同时,还有些确诊病人的密切接触者在经过医学观察后,或被确诊或被解除观察。基本流程如下图所示:
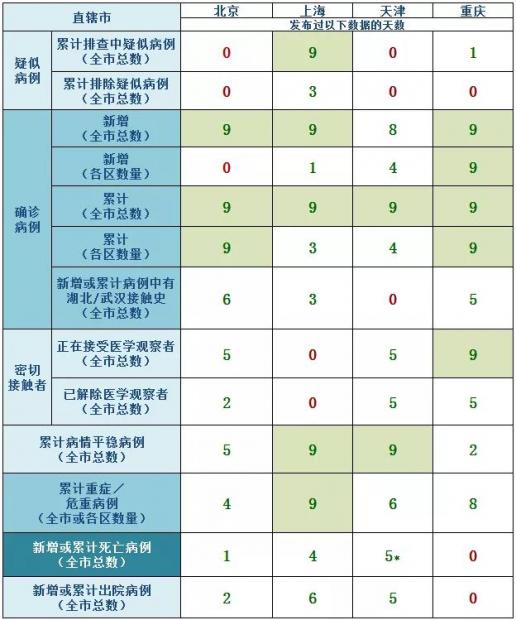
在疫情发展和防治过程中,各直辖市卫健委发布了疑似病例、确诊病例、密切接触者、病情平稳者病例、重症危重者病例、死亡病例、出院病例等统计数据。下表中展现的是截至1月29日中午12点,我们对四个直辖市的卫健委发布过的疫情数据进行比较分析的结果。
备注:
1.截止时间:1月29日12时
2.绿色背景色表明所有天数都发布过该项数据。
3.*表明有报过该项数据,但数据值为0,即没有出现死亡病例。
从上图可见,各直辖市发布的疫情统计数据并不一致,没有一个直辖市连续发布了每项数据。有些直辖市曾经发布过、但之后不再发布某项数据;有些直辖市之前未发布、但从某日起开始发布某项数据;有些直辖市断断续续地发布某项数据;有些直辖市则从未发布过某项数据。可能是因为疫情数据发布的范围和颗粒度还没有统一的标准,各直辖市还在不断摸索和探索中。
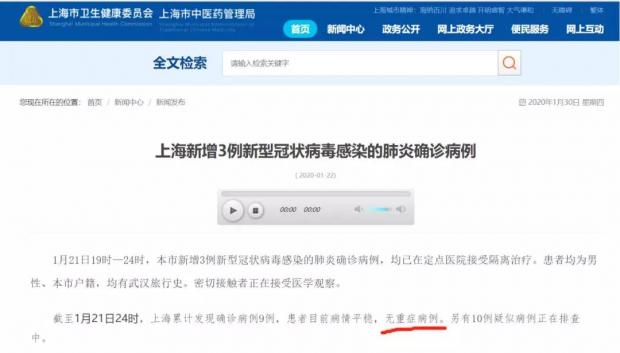
在疑似病例数据上,只有上海持续每天发布“累计排查中的疑似病例数据”,且从27日起持续3天发布“累计排除的疑似病例数据”。重庆仅在一天发布过累计排查中疑似病例数据,其他直辖市未发布该项数据。
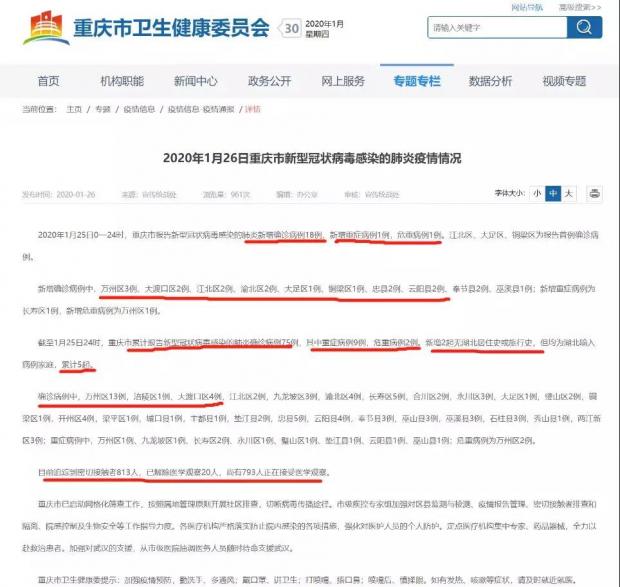
在确诊病例数据上,四个直辖市都发布了新增确诊(全市总数)、累计确诊(全市总数)与累计确诊(各区数量)三项数据。上海从27日起开始发布各区累计确诊病例,29日起开始发布各区新增确诊病例。只有重庆持续发布了关于确诊病例的每一项统计数据(见下图)。
在密切接触者数据上,除了上海,其余三个直辖市都发布了正在接受与解除医学观察的密切接触者数量,其中重庆能够长期持续发布。
在病情平稳病例的数据上,各直辖市都曾在疫情通报中发布过,上海与天津还做到了每天持续发布。但不同直辖市在表述标准上略有差异,上海似乎是将“病情平稳”作为一种病例类型,来区分于危重病例;天津则以“轻症”区分于“重症”,而将“病情平稳”作为一种病情状态来同时描述轻症和重症病例(见下图)。但在两地发布的页面中都没有找到这些专业词汇的解释说明。
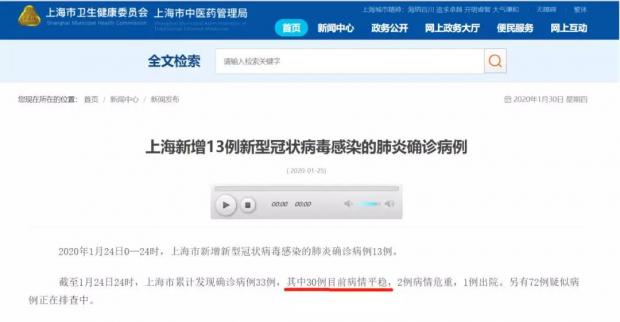
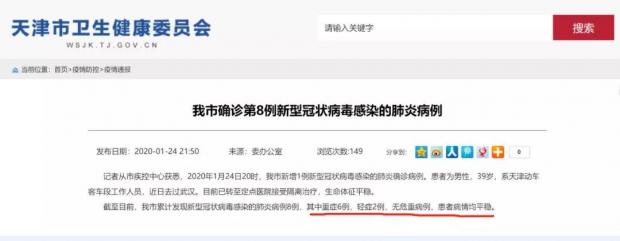
普通公众大都不是医学专家,政府在发布专业性数据时用词标准不统一或没有配备详细准确的备注说明,会使公众无法准确地理解和利用数据,甚至产生误读或误用。
在累计重症/危重病例数据上,各直辖市都曾发布过,上海和重庆能够做到持续发布。而且,上海在当天并无重症病例出现的情况下,仍然坚持发布该项数据(见下图),只是将该数据的数值标为“无”,体现了数据发布的规范性。而有些直辖市未能每天连续发布该项数据,使公众无法区分到底是 “没有报”该项数据,还是该项数据的数值为0。
在死亡病例或出院病例数据上,除重庆外,其余三地都发布了该项数据,但北京发布的天数较少。同样需要点赞的是,天津在当日没有出现死亡病例的情况下,仍然发布了该项数据,只是报告的数值为“无”,避免了数据缺失。
哪个直辖市发布的有关病人情况的数据最多、最细?
上面发布的这些统计数据是对原始数据进行加工和归总后形成的粗颗粒度的结果,并不是一手的、细颗粒度的原始数据,而后者才具有更大的分析和利用潜力。
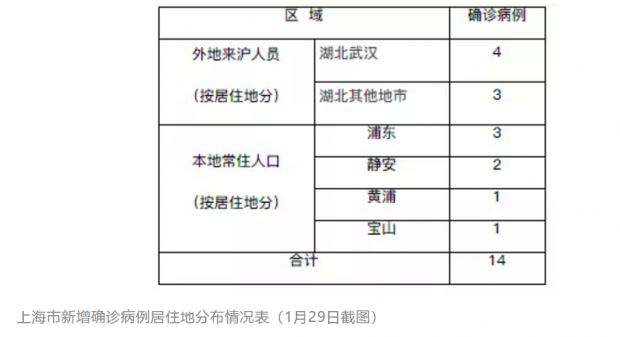
举个例子,上海市曾发布了这样一条文字信息:“截至1月26日24时,上海市累计发现确诊病例53例,其中,男性29例,女性24例;年龄最大88岁,最小7岁。”这些数字都是统计数据。其中提到的7岁到88岁这个年龄区间非常大,无法告诉我们在这个区间内,确诊病人主要集中在哪个年龄段?更无法告诉我们某一个年龄段的病人是男性多还是女性多。
对于以上这些问题,只有在获得统计归总前的、原始的、细颗粒度的病例个体数据并对其进行分析之后才能得到答案。
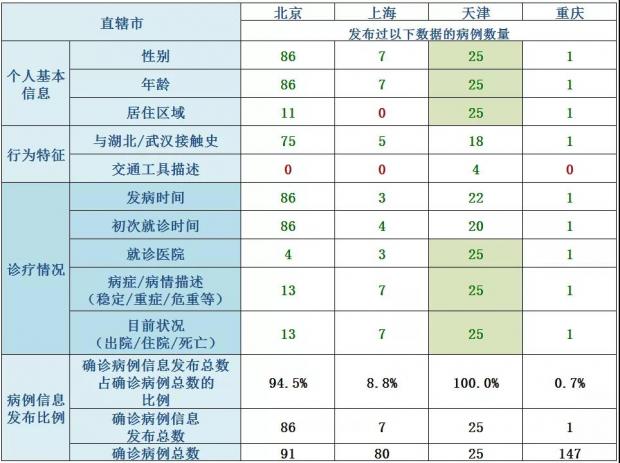
那么这四个直辖市都发布了哪些病例个体数据呢?下面这张表展示了截至1月29日12时,4个直辖市发布的已确诊病例个体数据的情况。这些病例数据大致可分为三大类:个人基本信息、行为特征和诊疗情况。
备注:
1. 截止时间:1月29日12时
2. 绿色背景色表明所有病例都发布过该项数据。
总体上,各地发布的病例数据在个体数量和字段数量上各有差异。同样,没有一个直辖市发布了所有病例个体的每项数据,各个直辖市发布的病例数据或是不完整,或是不连续。
相对而言,天津和北京发布的病例个体数据最多,分别为25个和86个确诊病例的数据,占当地所有已确诊病例总数的100%和94.5%。天津发布了所有25个病例的六项数据,分别为性别、年龄、居住区域、就诊医院、病症/病情描述和目前状况。
个人基本信息:
在性别和年龄上,天津发布了所有确诊病例的该项数据;北京发布了超过九成确诊病例的该项数据;而上海仅发布了7例;重庆仅发布了首例的该项数据。
在居住区域上,天津发布了所有确诊病例的的该项数据;北京发布了11例;重庆仅发布了首例的该项数据;上海未发布该项数据。
行为特征数据:
在与湖北/武汉接触史上,北京发布了超过八成确诊病例的该项数据(如下图);天津发布了超过七成确诊病例的该项数据;而上海只发布了5例,重庆仅发布了首例的该项数据。
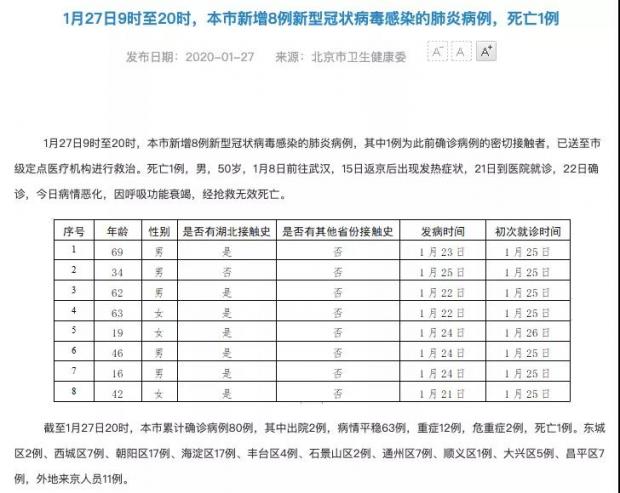
在交通工具描述上,仅天津发布了4例确诊病例的该项数据(如下图),其余3个直辖市均未发布该项数据。

诊疗情况数据:
在发病时间和初次就诊时间上,北京发布了超过九成确诊病例的该项数据;天津发布了超过八成确诊病例的该项数据;上海发布了不足一成;重庆仅发布了首例的该项数据。
在就诊医院上,天津发布了所有确诊病例的就诊医院(如下图);北京发布了4例已治愈病例的就诊医院;上海发布了3例已治愈病例的就诊医院;重庆仅发布了首例确诊病例的就诊医院。
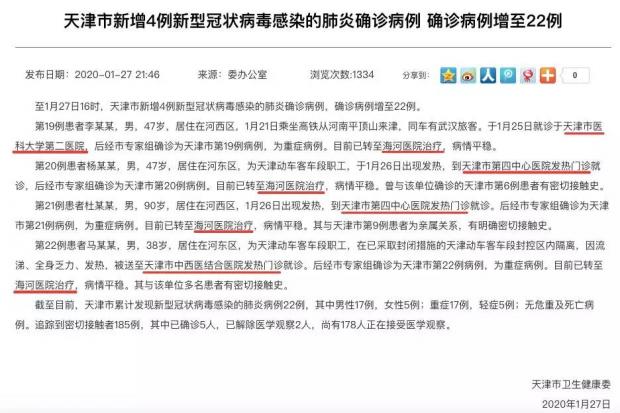
在病例的病症/病情描述(稳定/重症/危重等)和目前状况(出院/住院/死亡)上,天津发布了所有确诊病例的该项数据;北京在1月21日和22日发布了新增疫情病例以及此后的治愈出院病例的该项数据;而上海发布了7例,重庆仅发布了首例的该项数据。
总体上,天津发布的病例个体数据人数最多,字段最全。
然而,需要指出的,天津对极少数病例同时公布了患者的姓氏、性别、年龄、所在镇及就诊医院(如下图)。这些数据如单独发布风险都不大,但针对一个病例同时发布,就很容易被结合起来进行分析,从而锁定到患者本人,暴露其隐私。
事实上,我们并不需要知道每个病人的姓名、身份证和住址等个人信息,而只需要一些匿名化的病例数据就可以得出有用的分析,也不会侵犯到病人的隐私。

哪个直辖市发布疫情数据的频次最高?
各直辖市卫健委均从2020年1月20日或1月21日开始在官网上发布疫情数据。上海开始发布的时间比其他直辖市早一天。北京和天津发布的总次数及每日平均发布次数最多,每日根据疫情进展不定时发布多次,更为灵活机动。
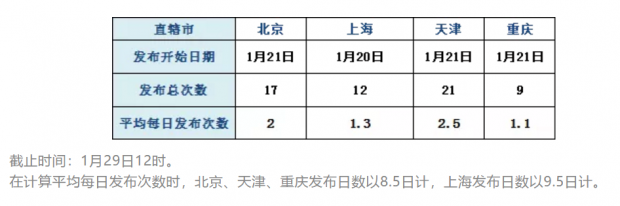
然而,无论发布次数多少,如果想要分析一段时间内的数据,是无法从某一条通告里获得全部数据的,而是需要去翻找以前发布的一条条通报,把里面的数据提取出来,再整合成一张大表。
也就是说,目前政府发布的疫情数据以碎片化的方式散落在不同时间发布的、位于不同页面上的、以不同名称出现的通告里。公众如果想要分析这些数据,需要先具备一定的能力,然后再花大量时间去把这些数据提取和整理出来。
哪个直辖市发布的疫情通报字数最多?
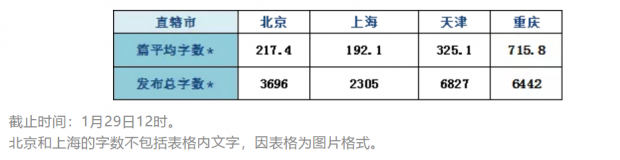
从单篇平均字数和发布总字数来看,重庆单篇平均字数最多,天津的发布总字数最多。重庆的单篇平均字数较多在一定程度上是因为通报中除了疫情数据外还附带了当前防控措施、卫健委提示等信息。
目前从对这四个直辖市的分析中未发现通报字数与数据发布的数量质量之间存在明显的相关性。
政府为什么要开放疫情数据?
面对疫情,公众只有掌握了充分的信息,才能做出更理性的决策和行为。在互联网和社交媒体时代,公众如果不能及时获得来自政府的权威数据,而只能被网上网下各种真真假假的小道消息轰炸,只会增加他们的恐慌感,作出不利于疫情防控的行为。因此,让公众在疫情初期就能获得充分的信息,有助于其加强自我防护,减少出行聚会,防止疫情扩散,也有利于减轻社会的恐慌感。
进入大数据时代,在疫情发展和防控过程中,公众不仅需要获得相关知识和信息,还需要获得完整的、标准的、一手的、及时的、细颗粒度的、结构化的、可机读的数据来进行解读和利用。
然而,通过上面比较分析发现,目前政府部门发布的疫情数据普遍呈现为一种以文本或图片形式存在的、碎片化的、标准不一的、不完整的、不连续的、粗颗粒度的形态。这样的数据对公众来说,不方便找到,不容易看懂,也不便于被分析利用。结果是,虽然政府已从他们的视角出发,以他们习惯的方式发布了疫情数据,但老百姓却没有获得感,他们的数据需求还远远没有得到满足。
事实上,自疫情发生扩散以后,大部分公众并不是从各个政府网站上直接获取和解读疫情数据,而是通过类似“丁香园”等媒体制作的数据可视化应用来间接获取和解读政府发布的数据。这类应用搜集和整合了全国和各省市政府发布的疫情数据,并通过表单和可视化的方式来进行生动的呈现。相较于政府网站上发布的文本通告,这种数据呈现方式对于公众来说,更为系统、直观和清晰(见下图)。目前,“丁香园”的访问量已达到10亿多次,深受公众欢迎,并且还在不断迭代升级,提升用户体验。
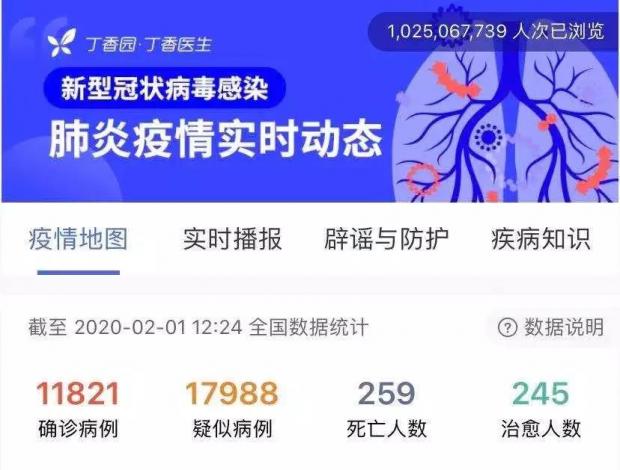
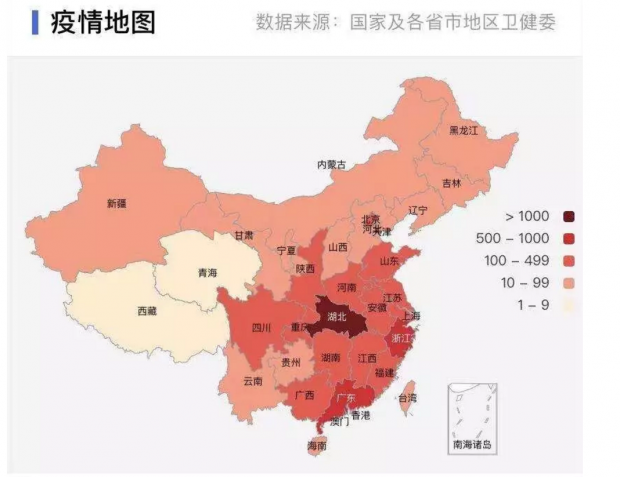
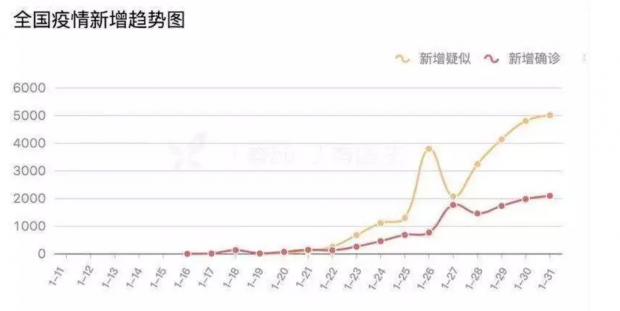
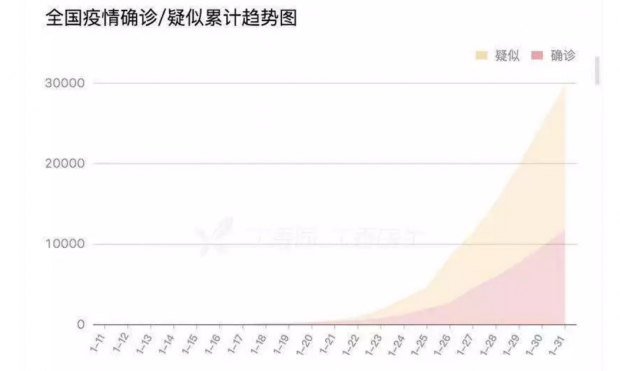
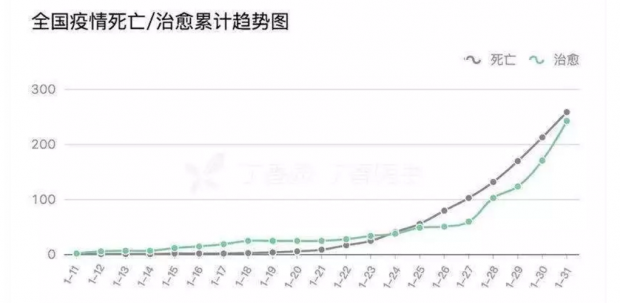
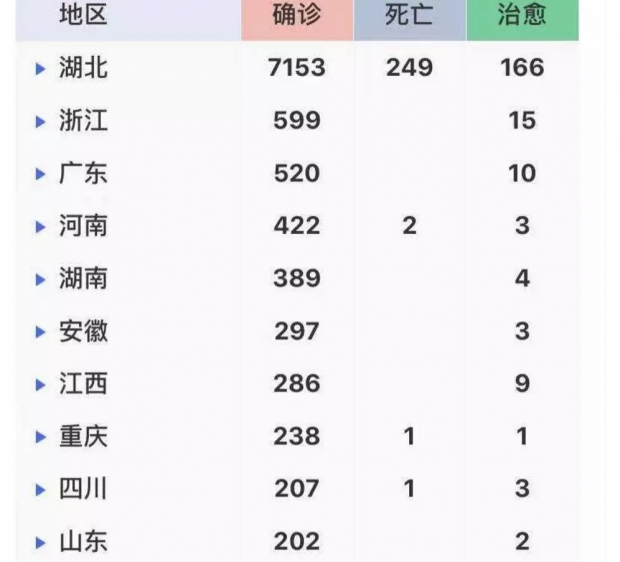
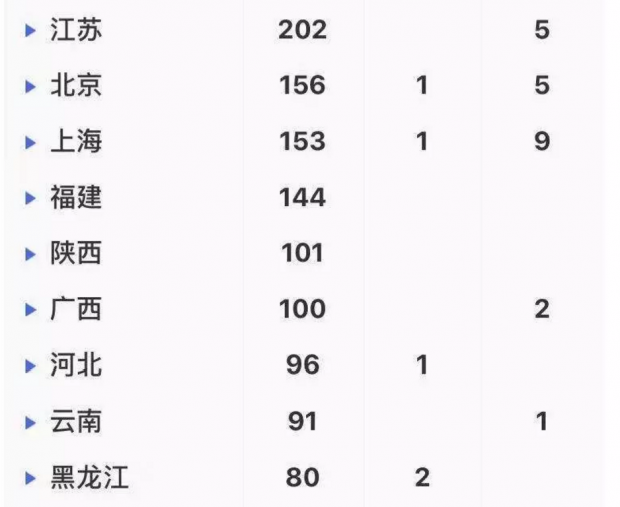

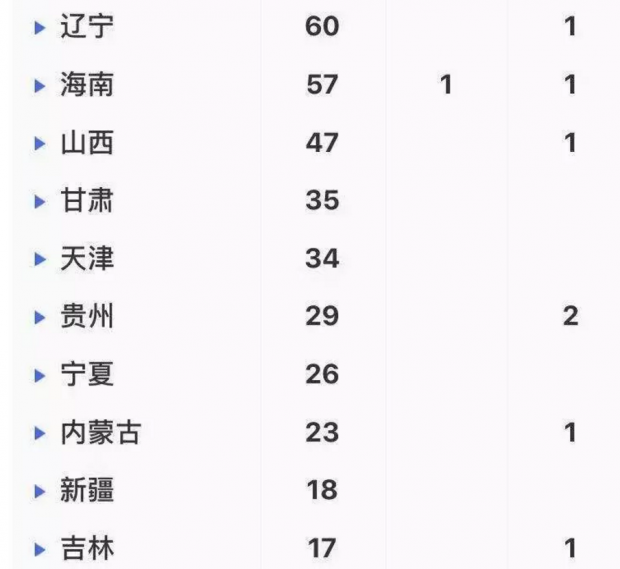
“丁香园”展示的数据虽然来自于“国家和各省市卫健委”,但可以想见,他们为了实时采集和整理各级各地政府发布的碎片化的、不符合标准格式的数据需要花多少时间和精力。同时,由于各地政府发布的数据在完整度和颗粒度上都还存在不足,这些市场化应用也无法提供出更全更细的疫情数据。
假设政府部门能把符合标准的、优质的疫情数据开放出来,像“丁香园”这样的机构就可以不必再花费大量时间去采集和整理数据,而可以把精力集中在将数据应用做得更好用更细致,给用户带来更好的体验上。同时,其他也得到了这些疫情数据的机构还能与“丁香园”形成竞争,最后看谁能给用户带来最好的体验。
在这个过程中,政府把数据开放出来,专业机构把数据开发成各种应用,携手为社会公众带来了收益。实际上,政府和市场以数据为原料实现了一种合作。毕竟,应对疫情不能只靠政府一方来孤军奋战,还应充分调动社会上的各种专业力量来积极参与。
然而,要真正实现这种合作共赢,有一个重要的前提不可或缺,那就是政府要开放数据。作为一种基本原料,数据就像大米,可以被用来做成各种各样的饭,但如果没有数据,巧妇也难为无米之炊。
政府应该如何开放疫情数据?
那么,政府开放的数据应符合哪些基本标准呢?目前,国际上普遍认为数据开放应符合以下八条基本原则:
第一,完整(Complete)。除非涉及国家安全、商业机密、个人隐私或其他特别限制,所有的政府数据都应开放,以开放为原则,不开放为例外。
第二,一手(Primary)。开放从源头采集到的一手数据,尽可能保持数据的高颗粒度,而不是开放被修改或加工过的数据。
第三,及时(Timely)。数据尽可能以最快速度发布,以保持数据的价值。
第四,可获取(Accessible)。尽可能地拓宽开放数据的用户范围和利用目的。
第五,可机读(Machine-readable)。对数据进行合理的结构化处理,使之可被计算机自动处理。
第六,非歧视性(Non-discriminatory)。数据对所有人都平等开放,无需登记。
第七,非专属性(Non-proprietary)。数据以非专属格式存在,从而使任何实体都不能独占和排他。
第八,免授权(License-free)。数据不受版权、专利、商标或贸易秘密规则的约束,除非有合理的隐私、安全和特别限制。
需要特别强调的是,开放疫情数据的同时还应严格保护好病人的隐私。一方面要满足公众的知情权,尽可能地将公众关心的数据全面、及时、准确地发布出来;另一方面,也要严格保护患者的隐私,防止个人数据的过度披露对患者造成伤害。政府部门需要把握好保障公众的知情权和保护病人的隐私之间的平衡。
总之,在大数据时代应对疫情,政府应围绕公众的数据需求,从用户的视角出发,将疫情数据以完整的、标准的、一手的、及时的、细颗粒度的、结构化的方式开放出来,并提供便捷的方式,配备必要的描述说明,以方便普通公众查找、获取和理解数据,也利于社会力量对数据进行开发利用,从而消除公众恐慌,压缩谣言空间,提高社会参与度,提升政府公信力,释放数据的社会价值。
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}