
编译:ZoeY、王一丁、Ivy、jiaxu、钱天培
5金9银7铜——这是俄罗斯小哥Vladimir的Kaggle成绩单。
凭借这一成绩,Vladimir也荣获了Kaggle的最高荣誉——竞赛超级大师(Competitions Grandmaster)。Kaggle至今已成立8年,注册用户超过100万,现仅有100余名Grandmaster,非常珍贵。
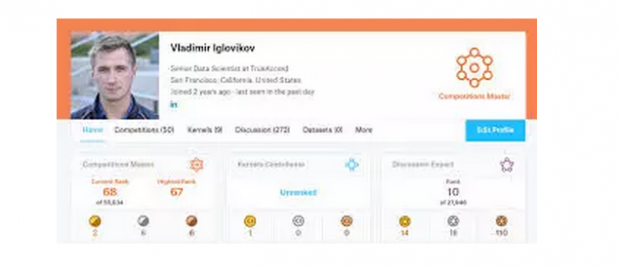
除此之外,他还曾获得过“MICCAI 2017胃镜图像分析比赛”第一名,“MICCAI 2017汽车影像遮盖比赛”第一名,“2018 CVPR楼宇识别比赛”第二名……
真是个一路开挂的数据科学家!
不过,这位开了挂的小哥其实并非科班出身。从取得理论物博士学位后,他就开始参与各类数据竞赛。兜兜转转,他也最终来到Lyft公司自动驾驶部门,成为了一名真正的数据科学家。
最近,这位小哥组织了一场“粉丝见面会”,回答了好奇网友的诸多问题。文摘菌对这次问答进行了编译整理。
Kaggle超级大师究竟如何炼成?让文摘菌带你一探究竟。
问:你是如何兼顾全职工作和kaggle竞赛的?

答:我把参加Kaggle竞赛当作是我的第二份全职工作,只不过是不发工资的。当然,我这么做是有原因的。Kaggle活跃用户都很喜欢寻找新大陆,我也不例外。当我从学术界转到业界后,我开始参加挑战赛。在那时,我需要一个高效的方式尽快了解机器学习可以解决的问题类型、学会使用相关工具、拓展我的思维方式来适应机器学习这片新土地。
之后,我在Bidgely开始了第一份工作,那时我更加迷恋Kaggle了。工作时间我研究信号处理相关的任务,下班后几乎花整晚时间研究那些与表格数据有关的竞赛。那段时间我的工作和生活有些失衡,但是与我汲取的大量知识比,一切都值了。
之后,我准备好进入机器学习领域了,所以我换了工作,加入TrueAccord公司,在那里我做过到很多传统机器学习的工作。但那还是不能满足我的求知欲,所以我继续研究Kaggle上的课题。那个时候我工作日白天做传统的机器学习课题研究,晚上和周末研究深度学习的课题。这导致我的生活和工作更加失衡了。但功夫不负有心人,我不仅学到了更多知识、更多技能,同时还获得“Kaggle大师”称号。一分耕耘一分收获,后来我得到了Lyft公司第5级的工作,主要研究如何用深度学习技术解决自动驾驶项目中的问题。
后来我渐渐减少了在Kaggle的时间。但是我仍然很积极的学习。在工作中我遇到了很多有意思的与计算机视觉相关的问题,我尝试去探索Kaggle以外的新大陆。我也时不时参加一些比赛,但那主要是为了更好地理解竞赛的主题和参赛者遇到的瓶颈,然后去论坛看大家分享出来的信息时,我就能学到更多。
问:你是怎样安排每天的时间,让自己变得如此有效率的?
答:首先,我不太确定自己是不是很有效率 :) 我总是在寻找新的方式来优化我的日常安排。
生活中总有各种各样的问题需要去解决,也有各式各样的活动想要去参加。但并不是所有活动都是同等重要的、好玩的。所以我总是给需要做的事情排序。关于这个话题,市面上有很多书籍进行了精彩的讨论,我在这里推荐两本,供想要提高效能的大家参考:
-
《优秀到不能被忽视:擅长比喜爱更重要》(So Good They Can’t Ignore You: Why Skills Trump Passion in the Quest for Work You Love )
-
《深度工作:如何有效使用没一点脑力》( Deep Work: Rules for Focused Success in a Distracted World)
工作日我早上六点起床,然后去攀岩馆。这有助于我保持身材,并且可以让我精神抖擞的迎接新的一天。结束攀岩,我开车去上班。我们的自动驾驶工程中心位于Palo Alto,这对我来说有点难过,因为我更喜欢生活在城市。开车是有趣的,但是上下班通勤不是。为了让我在路上的时间变得更有效率,我会在车里听有声书。虽然我不能在开车的时候很专注地听书,但是很多好的资源,例如提高软技巧或者商务领域的书籍,开车的时候听是特别好的。
如果我说我的工作和生活平衡的很好,那是骗人的。但当然,我也会花很多时间我的朋友相处、参加不同的活动,幸运的是旧金山很热闹,不愁没有活动参加。与此同时,我仍然要学习,我要保持在机器学习领域的熟悉度,不只是为了工作,更是为了扩大视野。所以有些晚上,我会去阅读科技文献,或者为竞赛、副业、其他开源项目编程。
说到开源项目,我想借这个机会宣传一下由 Alexander Buslaev、 Alex Parinov、Eugene Khvedchenia和我联合创办的图像增广技术资料库,这个平台上的资料是我们几人对计算机视觉研究的精华提炼。
最后分享几个“雕虫小技”。
和MacBook相比,我更喜欢Ubuntu + i3 系统,我主观的认为这帮助我提升了10% 的效能。
我很少使用Jupyter ,除非有EDA 或者可视化的项目。我的大部分代码是用PyCharm写的, 用flake8检查, 然后发布到GitHub。机器学习的很多问题都很相似, 找一个更好的代码库,不要总写重复的代码,想一想怎样重构代码,虽然这样做刚开始会降低你的效率,但是之后会大大提高你的效率。
我一有空就写单元测试文档。每个在数据科学领域的人都知道单元测试的重要性,但并不是每个人都会花时间去写单元测试代码。Alex Parinov写过一份很好的教程,指导大家由浅入深。你可以跟随这份教程,以及根据你的需求编写更多测试代码,放在Academia或者Kaggle ML pipelines。也许你在工作中已经在这么做了。
目前我正在试用版本管理工具DVC,希望这个工具可以优化ML pipelines的输出结果,提升我的代码使用率。
我尽量不使用鼠标,所以有时候我会在纸上写下快捷键用法,并把这张纸放在我面前,尽可能多地使用快捷键。我不太使用社交网络。也每天很少查看邮件。
我会在每天早上列出我这天想完成的事情,并尽量全部完成。我使用Trello协助我完成规划和管理。
我尽量避免让我的时间过于碎片化,因为大部分任务都需要注意力集中才能完成,所以经常转换注意力不太好。
以上的观点都比较常见,我也没有神奇的法术,见谅了!
问:你是如何紧紧追随科技前沿的?
答:我不会说我真能做到紧紧跟随前沿技术。
机器学习领域是个充满活力的领域,几乎每天都有新的论文,竞赛,博客文章和书籍在产生,数量之多甚至不可能将其一一概览。实践中,当我遇到一些问题时,我会专注于最近的结果进行深入研究。完成相关问题后,就进入到对下一个问题的研究。 也因此,对于那些我没有实践经验的领域,我只了解一些理论层面的知识,我觉得也这OK。与此同时,因为处理实际问题而学到的专业知识已经很多了,而且越来越多,这样的事实对我在新的领域开展机器学习工作有很大裨益。
这也意味着,因为我已经对很多问题有了实践经验,因此在遇到新的类似问题时,我就可以很好的上手去解决。
我也参加NIPS,CVPR这样的会议,借此了解目前的技术究竟能做些,不能做什么。
问:有一段时间(比如4 - 5年前),拥有在非ML特定领域的博士学位(Physics,MechEng等)会非常受雇主青睐。 目前,我觉得情况发生了变化,如果将非ML领域的博士与ML的MSc进行比较,看起来IT / ML行业将更喜欢雇佣后者来担当ML工程/开发人员角色,不过我对于研究人员是否也是一样就不是很确定。
就目前而言,你对非博士学位人员想将工作领域到ML行业有什么看法?博士学位会对他们在公司获得研究职位有所帮助吗?与相关的MSc相比,对其它专业的博士而言,他们的专业对他们在ML行业找工作有什么帮助吗?
答:这个问题不好回答,我只能随便说说我的想法。
物理学是一门伟大的专业。 即使我可以回去在物理和CS之间做出选择,即使知道我后来会转方向到CS,但在做选择时,我还是会选择物理。
最主要原因是,物理学和自然科学令人感到振奋。
ML会告诉你我们周围这个多姿多彩又令人兴奋的宇宙是如何动作的吗?显然不会, 但是物理学会。
不单是这个原因,将研究领域从物理学转到ML的原因之一在于这其中没有太多困扰,因为专业的物理学知识和理论不仅让我明白那些有关量子力学、相对论、量子场论和其他高度专业化的知识,同样使我有了很重要的数学、统计学、编码等专业技能。
物理教你如何以有条理的方式在严谨的理论和实验之间进行操作,这也是任何一个ML从业者所应有的基本技能。如果不上大学而只是自学,想要掌握物理或高等数学几乎是不可能完成的事。在此方面,我坚信,深度学习的下一个重大突破将会在我们弄明白如何将就物理,化学和其他高级领域开发的高级数学应用于机器学习时发生。现在我们只要知道大学一年级的数学就可以解决计算机视觉中的问题。
现在所有这一切都意味着,数学对于我们的研究和工作并非阻碍(反而对于实际应用而言是超前了),这就是为什么那么多来自数学/物理/化学和其他STEM领域这些获得的额外的毕业生觉得自己做了无用功,他们的很多知识对于解决大多数业务问题几乎无用。互联网上充满了这些类型的博客文章:他们有很多专业知识; 他们拥有博士学位,他们在学术界熬过了许多年,却最终无法获得有意义的高薪工作。
另一方面,能够编写代码在任何地方都是必不可少的,这就是为什么当潜在的雇主在一个熟悉数学的人和编写代码的人之间选择时,第二个几乎总是会赢。
但我相信它会改变。不是现在,而是在未来的某个时刻。
需要注意的是,你阅读的论文和你在大学学习的课程可能与你在行业中所需的技能组合并不直接相关。这是事实,但我不认为这是一个大问题。
通常,你需要了解在工业中作为数据科学家或软件开发人员工作的事情,你可以自己学习这些你没法在大学学习的东西。人们在学到的大部分有关工业界中应用的东西公司的全职工作中获得。
在我写我关于理论物理和数据科学的研究的论文时,我试着找一份工业界的工作,但是很难。
我没有想要的那份工作所必需的知识; 我不明白硅谷中的事情是如何完成的,不知道自己应该怎样才能符合条件。我对互联网知之甚浅,我唯一能想到又做的就是把自己的简历不断的发到一家又一家公司,然后是一次一次的面试失败,之后又在不断的失败中学习不直至自己达到要求。
我记得有一次我被问到我的论文解决了什么问题?我对面试官的回答是:我在做Quantum Monte Carlo。之后,我又试图对论文解释,解释它意味着什么以及我们为什么需要它,而面试官看着我问道:“这种技术如何帮助我们增加客户的参与度?”
我想对那些非CS专业人士来说,参与到ML中最有效的方法是参加CS部门的DS相关课程,比如在空闲时间学习DS / ML。幸运的是,有很多很好的资源。我要说的是,不妨试着找一位有兴趣将ML应用于他所研究的领域的教授。此外,我建议可以在科技公司申请ML相关的实习。对研究生来说,获得实习比获得全职工作更容易。
一般来说,不要高估你的专业/大学对你找工作产生的影响。一家公司之所以要雇用你,是因为他们认识付钱给你可以帮助他们解决面临的问题。
你的学位和专业只是评估你的能力的标识。当然,如果简历中什么都没有,那很难通过HR部门对简历的筛选,但同样要注意的是,不能把专业对就业可能影响力过分放大。
虽然听起来很傻很天真,但我还是要说:不要因为就业如何而选择一个专业,而要看自己对其是否热爱。
问:你觉得目前数据科学(DS)或者机器学习(ML)中有哪些有趣的问题值得被钻研吗?我的硕士生学习生涯还剩下一半,但是我现在还不确定将来会找机器学习里哪个方向的工作。我与一些人交流过,他们说算法的创新和改进(不包括使用各种库和插件堆砌出来的DS/ML算法)在机器学习领域中最有价值。你对这个问题有什么看法呢?可不可以给一些关于如何选择职业方向的建议呢?
答:我觉得DS/ML中非常有趣问题并不是目前被广泛研究的主流问题。研究主流问题的人实在是太多了,他们都乐忠于将ML应用于信用评分、推荐系统、零售等方面,想让数据变成钱,这实在是无聊。 但是如果你将DS/ML应用于数学、物理学、生物学、化学、历史、考古学、地质学或其他任何人没有尝试过使用ML的领域中,你可能会新开辟出一块天地。
关于如何选择职业,DS/ML与生物学或物理学不同,你从DS / ML中学到的技能能让你快速适应不同的研究领域。 当然,开发某些银行或者对冲基金的交易算法与开发自动驾驶汽车的算法是不一样的,但是只要你算法基础良好,你就会发现它们的差别并不大。
问:30岁(有学习基础,但不是数学/计算机科学专业)才加入机器学习社区会不会太晚了?还能赶上末班车吗?如果可以的话,你觉得最低要求是什么?
答:当然不会晚。90%的机器学习(ML)内容只需要用在理工科大学一年级所学的数学知识就能解决,所以不需要特别深奥的数学知识。数据科学中最常用的语言就是python和R语言,他们都属于高级语言,所以你可以从他们入门ML而不是一开始就死磕ML内容细节。
我建议你可以参加一些关于DS的网络在线课程,然后研究一些关于Kaggle的问题。当然,很多名词概念一开始听不懂,但是你只要坚持专注,慢慢就都懂了。
我举两个例子吧:
-
Kaggle顶级大师 Evgeny Patekha从40岁开始他的数据科学旅程。
-
Kaggle顶级大师 Alexander Larko 55岁时才开始参加Kaggle。
问:你认为技术领域的专业教育对赢得Kaggle比赛至关重要吗?你在工作中有遇到过相反的例子吗?
答:专业的教育当然是有用的,但并不是必要的。很多在Kaggle中取得好成绩的人并没有接受过技术领域的基础教育。最典型的例子就是Mikel Bober-Irizar,他是一名Kaggle顶级大师,但同时他也是一名高中生。
不过有另外一件事你需要记住,在Kaggle中学到的知识只不过是你在ML业界或学界所需技能的一小部分。那些在Kaggle中学不到的知识,你可以通过基础教育获得。
其实话说回来,就算你只有高中文凭,你也依旧可以成为Kaggle大师。
问: 你用了多久去学习数据科学和机器学习才成为了Kaggle大师?
答:我在2015年1月的时候决定转向研究数据科学。从那个时候起,我就开始在Coursera上学习在线课程。二月底的时候,我了解到了Kaggle并且注册了自己的账号,接下来的两个月内我就得到了我的第一块银牌。
问: 如果不使用云服务器,只使用一台简单的家用台式机,能在kaggle中得到高分吗?
答:我没有在比赛中使用过云服务器,但是我自己有两台计算性能较强的台式电脑。一台电脑拥有4张GPU显卡,另外一台拥有2张GPU显卡。没有计算性能强大的电脑不会影响你取得高分,但是会限制你尝试不同的解题思路。解题思路的数量与最终比赛结果密切相关,所以如果你需要大量时间训练模型,你确实需要购买一台高性能台式机。
在几次硬件更新后,我决定使用4个GPU的电脑做高负荷训练,使用双卡GPU的电脑做模型设计。

拥有一台高计算性能的机器是远远不够的,你还需要编写代码去充分利用它。
我从深度学习的Keras框架转向Pytorch框架,其中一个原因是因为Pytorch中的DataLoader模块更加强大。
因为imgaug方法实在是太慢了,所以我们编写了 albumentations ,它可以100%的利用CPU进行计算,但是没有办法充分利用GPU。
如果想加快从硬盘读取jpeg图像的速度,你应该使用 libjpeg-turbo 或者PyVips模块,而不是PIL、skimage甚至OpenCV模块。

问: 对于那些从Kaggle开始转向研究数据科学的人,你对他们有什么建议吗?特别是对那些首次参赛的人,最需要注重什么呢?
答:参加Kaggle比赛有很多种方式,但是如何最快速的获取比赛所需的知识,我觉得最有效的方法就是像黑客一样。
参加一些包括python编程基础和机器学习的在线课程。
加入一个Kaggle竞赛,如果你能够从头到尾的编写出完整的程序,那当然很好。但如果你是新手,这对你来说是比较困难的。你不妨可以去论坛复制借鉴一下别人的核心代码。
在你的计算机上运行程序,生成结果并且提交至Kaggle平台,就可以在排行榜上获取名次。在这个时候,如果出现了操作系统、驱动程序、库版本、I/O接口等问题,你可能会觉得要崩溃。但是你需要尽快习惯这种状况,如果你还不能理解那些核心代码里面的内容,这并不会有什么影响。
你可以开始调整一些参数,随便调都可以,然后重新训练你的模型,提交你的预测结果。说不定有一些参数的修改能够提高你最终的排名。不用担心这种做法是否合理,大部分人都是这么做的。不需要对代码中相关知识或者原理有深刻的理解,只需要做不停地调整就可以了。
为了超过那些只会盲目调参的人,你需要发展出这一种直觉,你需要能够感觉出什么方案可行或者什么方案不可行,这样你就可以更加高效地找出可行方案。在这一阶段,你就需要将学习作为实验的一部分。你需要从两个方向入手,首先就是在mlcourse.ai, CS231n网站上或者专业书中学习数学、统计学、如何编写代码等基础知识。通常情况下,自主学习这些知识是很难的,但是从长远的角度看,学习基础知识至关重要。其次,你会在论坛上看到很多与你试图解决的问题相关的新术语,你需要记住这些术语,这些都是你需要学习的新事物,为了在排行榜上拿到更好的名次,你需要去努力学习。需要注意的是,你不能只学习或者实验,你需要两个同时进行。机器学习是一门应用学科,你也不希望你成为一个书呆子只会学习知识而不会应用。没有实践的理论是愚蠢的,同时没有理论的实践也是盲目的。
竞赛结束以后,虽然你付出了巨大的努力,但是很有可能你的名次并不好看。这种情况其实很正常。你需要好好浏览论坛,看一看那些获胜者分享的解决方案,尝试着去找到更好的解决办法。当下一次你遇到了相似问题的时候,你会比现在好得多。
在不同的竞赛中一遍又一遍的尝试,你既可以到达顶峰。更重要的是,对于各种问题你都会有好的解决方法。同时,如果你在比赛、工作或者科研中遇到了一些机器学习的难题,你会拥有更好的直觉知道下一步该怎么解决。
问:作为一个有物理背景的研究人员,当比赛变成了一场大规模的过拟合,你会感到沮丧吗?如果答案是肯定的,你会如何解决呢?
答:通常来说,你需要对数据和指标过度拟合来取得良好的结果。这很正常且常见。许多年来,人们常常会过度拟合ImageNet数据库,新知识会在这一过程中产生。但要做这些需要对数据和指标的细微差别有足够的了解,这将是我学到新知识的地方。只要在挑战过程中我有所收获,我不介意做一些过度拟合。你可能会注意到,针对某一问题十分有效的策略和想法,会为其他问题提供一个参考,因为他们通常会存在一些普适性。
问:你对Kaggle的数据泄露情况有何看法?例如 Santander, Airship prediction, 和 Google Analytics , 使用Kaggle比赛的所泄露的数据是否合乎道德?
答:就我所知比赛的组织十分困难,因此当出现数据泄露的情况时,我也不想去责怪组织者。我也并不介意有些人从比赛中获取一些利益。我必须承认数据泄露有时使我对比赛失去信心。我认为Kaggle的管理者需要对可能的数据泄露列出一张清单,并在比赛前认真检查数据,防止类似情况一再发生。我也相信他们已经在做这方面的努力。
问:Kaggle的比赛对于深度学习工程师的业务和工作有多大帮助?
答:还挺难说的。Kaggle能够在一些小范围的领域快速提升你的重要技能。这些技能对某一些职位而言能使你获益良多,而对另一些职位却没太大用处。对于我参与过的所有工作,尤其是现在的自动驾驶领域而言,从Kaggle获得的技能对于我在学校或者其他地方获得的技能是一个强有力的补充。
但需要强调的是,就算能扎实掌握Kaggle的技巧也是远远不够的。有些东西只能在实践应用中学习。
成为一个Kaggle大师不是必须的,可能也不足以使你胜任某一项工作,但同时我也相信,如果一个人成为了Kaggle大师, 他的简历会脱颖而出,吸引到HR的注意,从而拿到技术面试。
问:成为大师之后参加Kaggle比赛有多大用处? 当你已经成为技术纯熟的数据科学家时,你还有什么动力去做Kaggle比赛?
答:我现在已经不太常参加Kaggle比赛了。但我开始关注一些与会议相关的竞赛。在MICCAI 2017, CVPR 2018, 和 MICCAI 2018等会议上,我的团队都取得了可喜的成果。一般竞赛的数据相对干净、完整。不需要太多的数据清理工作。这样你可以花更多精力在分析的技术上。在实际工作中,这样的情况是很少见的,通常数据收集才是整个策略中最为重要的部分。
问:如果没有数学、计算机或者其他相关专业的背景知识,人们可以在Kaggle(或者更广泛一些,在数据科学中)走多远?激情和学习的欲望能使你走多远?
答:如果你关注目标并且愿意学习,你便可以成为Kaggle乃至其他数据科学领域的顶尖人物。最困难的便是跨出第一步。只要下决心去行动并即刻行动起来,因为将事情推到明天意味着永远不会去做。
还从没有人问过我,是如何找到在某个比赛中能够帮助改进结果的靠谱的队友的 。我认为这是一个十分重要,但我以前从未在博客中提及的话题。
最常见的方式是:和感兴趣参与Kaggle比赛的同事、朋友组队。通常的结果是,一些人会努力参与,其他人则坐等被carry。这样的队伍能够取得一些成绩,但通常都走不远。
我认为以下方式对参赛者更为有效:
1.写下你自己的策略,或者重构别人在论坛上分享的策略
2.这一策略需要以合适的方式囊括从输入数据到提交结果的所有过程,并定义一些交叉验证的标准。
3.通过结合你所定义的标准和排行榜上的排名,你可以看到自已的进步。
4.你进行尝试性的数据分析,仔细阅读论坛内容,阅读文章、书籍以及从前相似竞赛的解决方法。此时你完全独立进行工作。
5.在某一时间点,通常在截止日期2-4周前,你会被卡住。你尝试了一切可能的方法,但都无法对结果有所改进。此时你需要你一些新的想法。
6.这时你可以看看排行榜上排名和你相近的用户或者和与你有类似想法的活跃用户进行交流。
7.首先,你的预测结果的平均值,会给你一个很小的但及其重要的起点。其次,通常而言你的方法会与别人的有所不同。只是通过列出你尝试过或没有尝试的方法,都会对你的学习有所帮助。第三,因为你们都认真参与了比赛,每个人都单独对数据进行了观察,对策略进行了梳理,并且都把这次比赛放在了较高的优先级上,这时你能找到的队友多半是靠谱的。
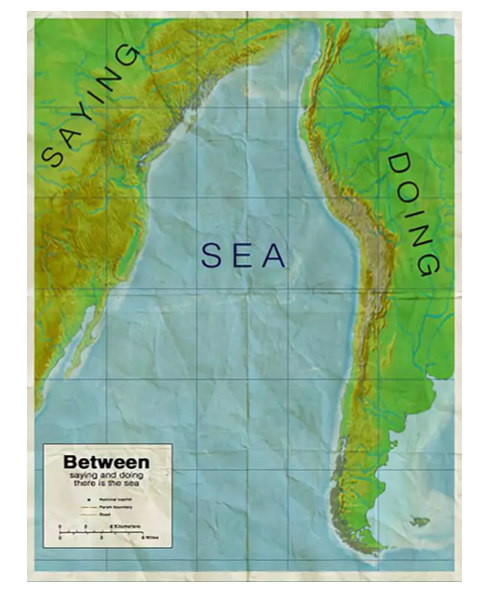
更重要的是,在有一个较为完善的策略之前,人们总是高估了他们乐于花费在比赛上的时间,且低估了可能遇到的问题。在组队过程中,排行榜起到了一个筛选的作用,用以确定你的队友跟你步调相仿。
在一些比赛中,专业知识也对比赛结果十分重要。例如表格类数据和相关特征工程或者是医学影像。此时你可能需要考虑将某个具有专业知识的人纳入队伍当中,即便此人并没有数据科学的背景。但这种情况比较少见。
与此同时,在实践中组织团队的方式则完全不同。用Kaggle里组队的方式进行实践是全然不明智的。
OMT
今年1月份,Vladimir在硅谷做过一次分享,聊深度学习创建汽车图像二进制分割模型,分享十分精彩,感兴趣的读者可以自行查阅。

录像:
https://www.youtube.com/watch?v=g6oIQ5MXBE4
视频:
http://slides.com/vladimiriglovikov/kaggle-deep-learning-to-create-a-model-for-binary-segmentation-of-car-images#/
相关报道:
https://towardsdatascience.com/ask-me-anything-session-with-a-kaggle-grandmaster-vladimir-i-iglovikov-942ad6a06acd

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号