
作者:魏子敏、蒋宝尚、王嘉仪
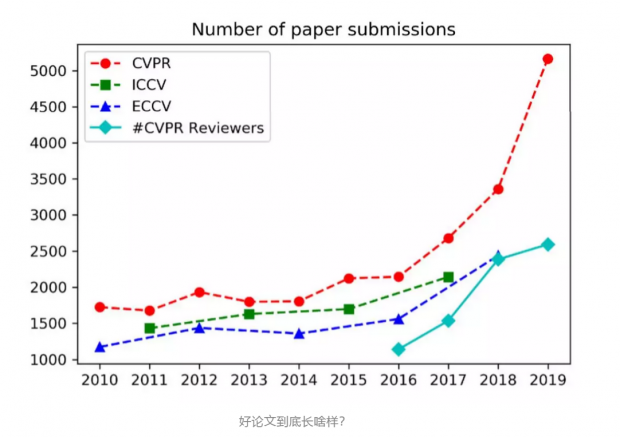
最近几年,研究者往计算机视觉领域的顶会投的论文越来越多。下图就能明显看出这一趋势,尤其是从2016年开始,论文提交的数量成指数型增长。如此激烈的竞争也让很多研究者颇为焦虑,到底什么样的论文更容易被顶会收录呢?
来自弗吉尼亚理工学院的Jia-Bin-Huang教授利用神经网络生成了一个识别好坏论文的分类器,通过输入论文的整体版面的视觉情况(就是看“脸“)来使分类器预测一篇论文应不应该被接收。
简单来说就是,这位研究者希望告诉大家,在论文内容不变的情况下,如何排版和撰写更能写出一篇“好论文”。
论文立刻成为了今天学术圈的热门话题,先来看看作者得出的几个结论:
-
好论文的特点:第一页中都有预告图用于说明主要思想,有各种表格/图表均衡插入论文各处,来展示验证性实验,有重要的数学方程式,以及有彩色图像列表来量化数据集的基准。
-
“坏论文”的特点:通常都写不满8页;前两页缺少数字和插图会让读者看不懂。
除了给研究者写论文的参考,作为CVPR 2019、ICCV 2019的领域主席,作者更希望通过论文中提到的“好坏论文分类器”,来减轻论文审核人的工作量。
最终得出的结论从数据上说值得一看。根据测试数据集的检验,此分类器允许0.4%容错率的情况下(拒绝0.4%好论文),能够准确的判断出50%的“垃圾”论文。总的来说,在论文数量庞大,审稿人有限的现实下,这个分类器能够大大减少工作量。
作者还自嘲了一下,自己这篇论文拿给分类器审核,得出的结论是97%的概率会被拒稿。
研究方法
研究方法
训练这个分类器所使用的训练数据集是2013~2017年CVPR和ICCV的会议论文,将这些数据丢进神经网络,根据论文的“颜值”,输出论文的质量。用2018年CVPR的论文进行验证,准确率达到92%。
此外,Jia-Bin-Huang还为广大的计算机视觉领域的研究者提供了一些建议,帮助他们提高论文美录用率。
研究方法的创新之处,是在训练数据的过程中并不是直接学习图像的映射。而是通过端到端的训练过程,以深度学习的方式重新审视“颜值”问题,从而能够学习特定任务的表现形式。
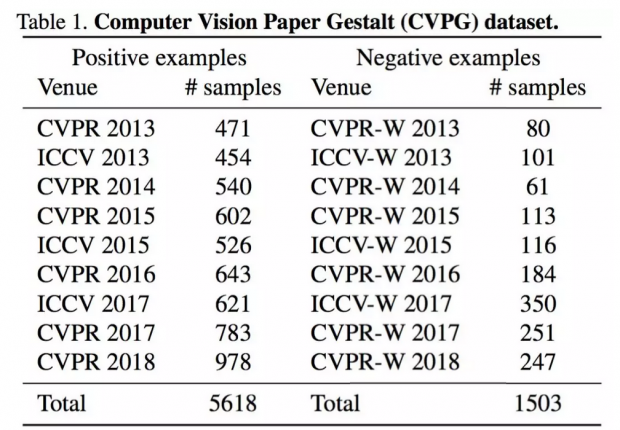
数据集获取:如何定义好论文和坏论文
数据集获取:如何定义好论文和坏论文
研究者从计算机视觉顶会的接收论文列表中收集正样本(好的论文)。
因为无法获取到被拒绝的论文,研究者用workshop的文章做一个近似。
当然,作者也对这一“差论文”的数据集进行了说明,毕竟非常多的workshop论文也会被重要会议收录。
同时,workshop的文章被认作“hard negative”,有很多文章被评论和复审标示出来从而得到了改进。

数据处理
数据处理
数据获得和处理。介绍一些平常运用这些数据集的具体步骤。
文件分类:一些workshop对于主要会议文章的有其特定的版面要求,例如需要6页的内容是与数据来源相关。分类就变得不那么重要。我们因而只保留7页多一点就已足够。
PDF2Image::我们用一种基于python的软件-pdf2image-把pdf文件转换成图片,然后剪裁成2 × 4网格大小。如果缺失第八页,我们就给它放一空页。原始转换后的图片有2200 × 3400像素那么大。
预处理:避免数据落项,我们会把首页标题去掉。如果不做这一步,分类器很多时候就会出现故障,它就只关注标题部分而忽视了整篇文章可视化的内容。

整体数据集获取:
https://github.com/vt-vl-lab/paper-gestalt
结论
到底好论文长什么样?
如何提高论文的录用率,当然颜值要过关啦,为此,作者利用GAN训练了一个好论文的生成器。数据集仍然采用2013~2017年的顶会数据集。训练硬件使用两个英伟达出品的芯片(NVIDIA Titan V100 GPU),整个训练过程大约需要一周的时间。

训练结果如何?上图是生成器生成的15个随机样本,他们都有共同的特点:图表,方程平衡布局。但是看起来很费力气,尤其是在生成数字和表格方面。这个难怪,因为,训练集中的每个图形和表格都是独立的。
用生成器修改过的文章看起来并不完美,所以它的利用效能还是很有限,尤其是它很难保持一个特定的模板来确定一个正要发表的文章的好坏。
此外,我们也想把坏文章变得好一点。没那么多文章可以练手,就用神经转积神经网络,对不一样的两图进行匹配。这很像我们之前用2013-2017的会议和workshop文章所做的实验。

坏论文应该是什么样子?上图所示,他们的特点是,整篇论文的页数没有达到8页。另外在论文的前两页缺少说明性的文字,可能也会被判定为坏论文。

好论文是什么样子,至少在正文第一页中要有让读者有看下去的冲动,例如在开头说明论文“性感”的主题思想,放上令人印象深刻的数学公式,以及用实验数据生成的漂亮的图像。
争议
争议
这一论文一经发布,立刻引发巨大争议。
不少同学评论,“有意思”,毕竟这一研究结果可以为自己在顶会上发文章提供一些参考。
但是也有非常多的质疑声。最大的问题就是,关于给好论文设指标这件事,本身就是个伪命题啊。
在reddit有同学直接指出,一旦这个论文套路被所有人熟知,那么明年的论文评审规则必定跟这个规则不一样了。
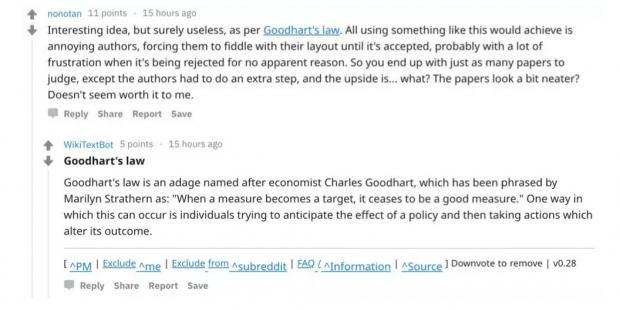
大家搬出了古德哈特定律来说明这一问题。

注:古德哈特定律(Goodhart's law) ,是以 Charles Goodhart的名字命名的,这是一个非常有名的定理:当一个政策变成目标,它将不再是一个好的政策。简单来说,它认为一项指标一旦成为政策制定的依据,便立刻不再有效。政策制定者会牺牲其他方面来强化这个指标,使得这个指标不再具有指示整体情况的作用。
不管如何,感兴趣的同学还是可以看看这篇论文。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号