记者:蒋宝尚
不管是初学者还是大魔王,只要浸润过数据科学和机器学习界,那么对于Kaggle一定不陌生。各路英豪在这个平台上实战练习、膜拜大神、打怪升级,用某个媒体人的一句话,“简而言之,Kaggle 是玩数据、机器学习的开发者们展示功力、扬名立万的江湖。”
为什么有这么多的数据科学家会在Kaggle花这么多的时间?kaggle最著名的就是竞赛了,那么具体的竞赛怎么做呢?
1 月 19 日,作为Kaggle的由联合创始人、首席执行官Anthony Goldbloom在“全球新兴科技峰会”中,回答了这两个问题。
以下Anthony Goldbloom的最新演讲,文摘菌做了有删改的整理~

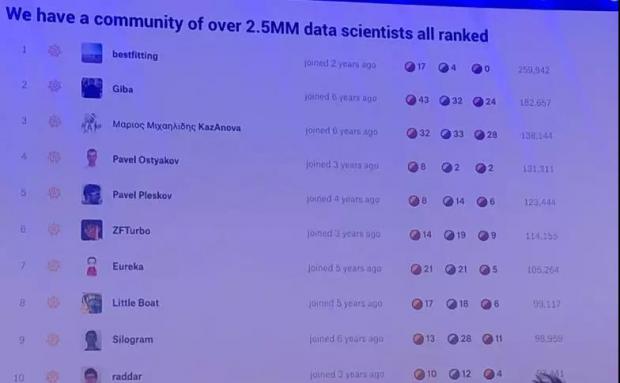
Kaggle聚集了大量的机器学习的专家以及大数据的专家最,截止到目前为止,差不多是有250万人了,在演讲的最开始,首先介绍一下我们在kaggle的工作。然后给大家说一下我们在kaggle学到的一些经验。
具体的竞赛怎么做
在Kaggle里面,我们做好几项不同的工作,分别是:竞赛、电脑的数据环境以及数据组的共享空间。
我们具体的竞赛怎么做呢?首先就是有公司会在我们的网站上面提出一个问题,解决这个问题会有奖金。
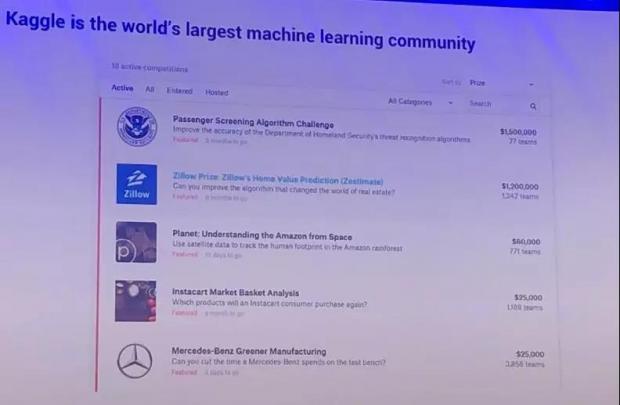
有一些奖金还是非常高的。例如上图,第一个是美国国土安全部,他们希望用算法能够帮助识别是否有人携带了武器,或者是携带其他的一些禁带品,他们希望这个算法更加的精准一些。这非常重要,因为过筛率如果太低,就意味着效率会变的非常的低。所以,他们是希望能够增加效率。
第二个是Zillow,Zillow其实就是在它的网站上面可以输入自己地址,然后根据房子里面有多少的卧室,多大的房间,有多少个浴室等估算房子价值。
Zillow那个竞赛,一开始他们可能和实际的房价是差了20%,然后呢,他们慢慢的调了一下算法,越来越接近正常价格。
更好的算法能够帮助他们找到正常的价格。为了解决这个问题,他们愿意提供超过100万美元做奖金。
其他的竞赛项目,奖金就没有这么多了,但是大家可以看得出来,越来越多的公司非常重视AI以及这样的算法。
还有卫星图像的竞赛,还有关于森林大火或者是森林减少率的图像分析的大赛。
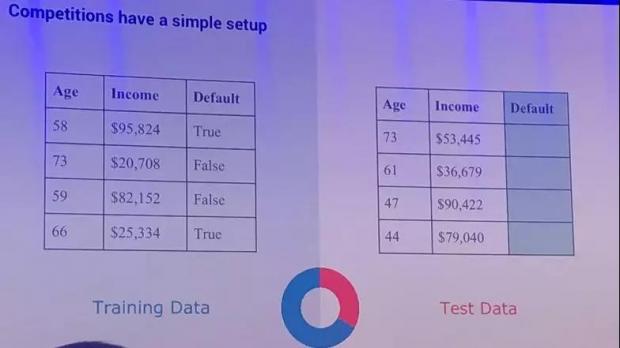
所以说,在kaggle里有各种各样的问题,包括不同的行业、不同的方面,这里面非常有意思的一点,就是所有的问题,都可以用差不多的方法来进行解决。当我们有两个数据集的时候,一个是训练集,一个是测试集,两者是完全不同的。训练集可以看到结果,测试集看不到结果。
测试组将采用类似的数据,这样的测试组可以帮助我们看一下算法是不是能够达到我们的预期值。对比不同的算法结果,我们也会把不同结果的对比进行公开。
对比提升算法准确率
所以说大家可以看到,大家如果能够把自己的结果进行对比的话,会有更多的激励,会把自己的算法调整的更好。
之前给大家说到的Zillow,一开始的准确率还差15%,最后准确率只差了5%。是不是5%就没有办法突破了,或者我们需要调整一些技术来弥补这5%。然后公司就会推出相关的竞赛,找到到底是什么原因,有没有办法突破最后的界限。
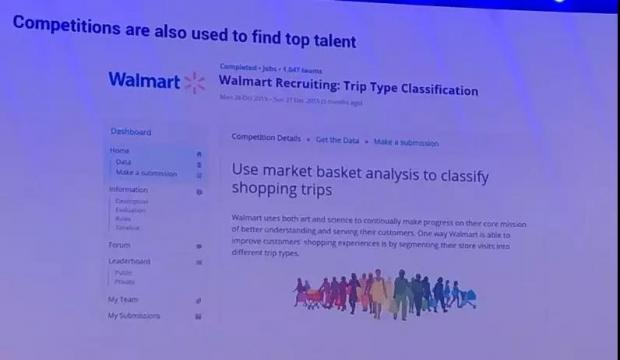
现在很多的公司也非常看重AI,一方面帮助他们解决问题,另一方面帮助他们找到人才。我们每半年都会有竞赛,我们和airbnb、Facebook联合组织相关的竞赛,帮他们找到相关的人才。
所以说,分享和学习是非常重要的,比如说你在竞赛里面的排名是15名。通过公开你可以知道第一名到底怎么做的以及第一名用采用的技术。有了这些,你在下次竞赛的时候就可以学习第一名所使用的技术了。
因为这里面有很多不同的人,这些人有可能是读AI的博士,或者有其他的一些业余选手。但不管是什么人,他都可以在这上面展示自己。
现在中国已经在社区里面规模排到第三了,第一是美国,第二大是印度。我们可以看到,有很多非常出色的竞争者都来自于中国。
Kaggle竞赛解决实际问题
为什么人们会竞赛,为什么公司会在kaggle网站上面放一些问题?
首先,竞赛非常重要,虽然说所有的网站都是深度学习,深度学习其实是在整个AI当中所使用的是比较小的数据组。
但对于这些问题来讲,那些小的数据组能解决的问题,传统的工具也可以帮助我们解决。但不管怎样,我们一开始必须要从不同的方面进行数据的探索,比如说我们会用数据绘制图标,所以说我们可以非常深入的了解数据。
在竞赛里面,人们第二步就是假设,数据之间的假设,例如在预测车销量的竞赛中,最主要的是用算法预测哪一个车可能会卖的更好。
其中有一个非常重要的因素是颜色,我们有两类:常规颜色以及非常规颜色。非常规颜色的车会比较好卖,因为根据这个假设买二手车的人可能会更喜欢一些比较另类的车,并且更爱保养。
通过这样的一种算法,我们也会进行头脑风暴,可以帮助我们更好的搜集不同方式或者不同方向的数据。
另外,我们进行调参,我们在进行数据的设计之后,再次把数据放在一个数据库当中,再进行分类、调参和模型融合。
其实,技术也是非常重要的,所谓的深度学习,也是竞赛者经常使用的技术。例如在图像的识别当中,经常使用的卷积神经网络技术,比如说卫星图像还有医学图像、自动驾驶也经常使用。
迁移学习解决小样本问题
即便说是数据库比较小的,但是我们做的还是非常的好,就是因为我们有所谓的迁移学习,也就是说我们可以把一系列的学习成果转移到其他更大范围的规模上。
这个学习的结果得到了转移之后,我们在进行一些调参,即便是有一些比较小的原始的数据组,比如说对于医学的图像,最后这个建立的模型也还是非常准确的,也可以帮助我们进行更好的应用。
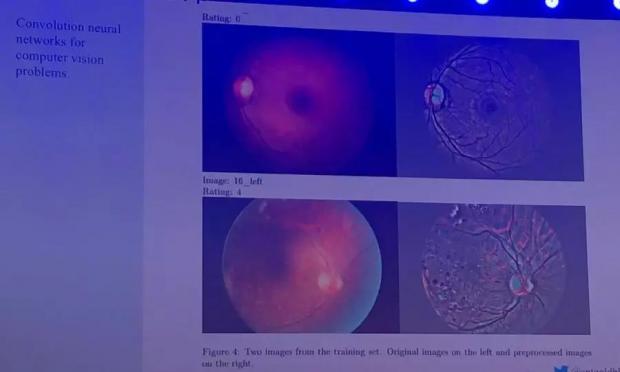
另外,我们发现深度学习在其他的领域也做的更好,比如说现在我们的神经网络做的非常得的好,比如利用卷积神经网络分析医疗图像,我们也是让竞赛者推断这个图片,去推断这个人是不是有癫痫或者是有相关的一些病症。
另外还有就是文本,因为文本有序列,一个字之后又是一个字,所以说这也可通过神经网络进行分析,所以说,我们在很多的问题解决方面,要判断有哪些技术是可以应用的,哪些技术是比较擅长的。
Kaggle竞赛中最重要的特征
特征一:我们发现我们的这些竞赛者都是非常有创造性的一群主体,竞赛中有一些问题是需要对特征进行相关的工程设计,所以说,在我们进行神经学习的时候,需要一些小办法来寻求帮助,判断看这个方法是不是管用,这个方法是不是能够提高效率,从而能够帮助我们把整体的效率提升。
特征二:我们竞赛者都是非常的重视如何对自己的模型进行测试的,大家建模之后会进行测试,然后在进行调参,进行改进......
在模型训练完成之后,进入测试阶段,做法是把用过的数据全部“扔掉”。然后用新的数据进行检验,也就是说我们要保证我们的算法不单单只是在原始数据上面可以做出准确的预测,而且在全新的数据面也可以做同样的结果。所以说,我们在进行模型的测试的时候,整体的过程是非常严苛的。
特征三:大家的编程能力非常棒。版本的控制是非常重要的,其实对版本的控制就能够意味着我们可以知道哪些版本更高效,哪些不能够奏效,其实在软件的这个领域当中,很多的数据科学家以及机器学习的专家都会使用各种办法来进行管理,所以说他们就会知道自己在代码在每个版本之间会有不同。
而且这也是非常重要的一个信息,让他们知道到底哪个版本是能够非常好的运作,哪些不太好。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号