阅读:0
听报道
编译:sailnj
CNN卷积神经网络问世以来,在计算机视觉领域备受青睐,与传统的神经网络相比,其参数共享性和平移不变性,使得对于图像的处理十分友好,然而,近日由Facebook AI、新家坡国立大学、360人工智能研究院的研究人员提出的一种新的卷积操作OctConv使得在图像处理性能方面得到了重大突破与提升,OctConv和CNN中的卷积有什么不同呢?
论文下载地址:
https://arxiv.org/pdf/1904.05049.pdf
CNN网络中的卷积层主要用来提取图像特征,如下图所示,利用卷积核(也称滤波器)对输入图像的每个像素进行卷积操作得到特征图,由于图像中相邻像素的特征相似性,卷积核横扫每个位置,独立的存储自己的特征描述符,忽略空间上的一致性,使得特征图在空间维度上存在大量的冗余。

OctConv主要基于于处理多空间频率的特征映射并减少空间冗余的问题提出的。
原文地址:
https://export.arxiv.org/pdf/1904.05049
下面文摘菌将从论文的四个部分展开对OctConv原理的阐述。
Why?—OctConv之诞生
文章摘要(Abstract)部分指出,在自然图像中,信息以不同的频率传输,其中高频率通常以细节进行编码,而较低频率通常以总体结构进行编码,同理卷积层的输出可以看做不同频率的信息混合,在论文中,研究者提出通过频率对特征融合图进行分解,并设计出了一种新的Octave卷积(OctConv)操作,旨在存储和处理在空间上变化缓慢的较低分辨率的特征图,从而降低内存和计算成本。与现存的多尺度方法不同,OctConv是一种单一、通用、即插即用的卷积单元,可以直接代替普通卷积,而无需调整网络结构。
OctConv与那些用于构建更优拓扑或者减少分组或深度卷积中信道冗余的方法是正交和互补的。
实验表明,通过使用OctConv替代普通卷积,能很好的提高语音和图像识别任务中的精度,同时降低内存和计算成本,一个配备有OctConv的ResNet-152能够以仅仅22.2 GFLOP在ImageNet数据集上达到82.5%的top-1分类准确率。
What?—初探OctConv
论文Introduction(介绍)部分基于CNN现存的空间维度冗余问题引出了下图:
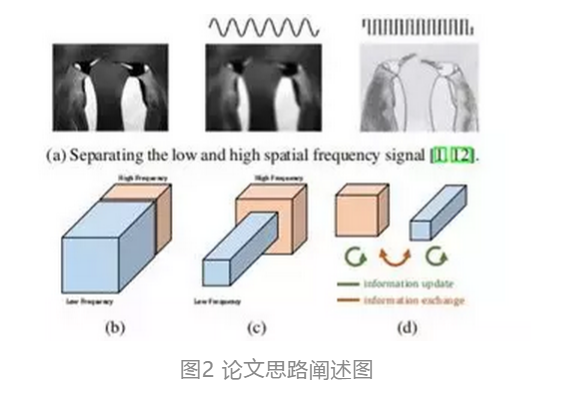
(a)动机:研究表明,自然图像可以分解为低空间频率和高空间频率两部分;
(b)卷积层的输出图也可以根据空间频率进行分解和分组;
(c)所提出的多频特征表示将平滑变化的低频映射存储字低分辨率张量中,以减少空间冗余;
(d)所提出的OctConv直接作用于这个表示。它会更新每个组的信息,并进一步支持组之间的信息交换。
具体解释为:如图 2(a) 所示,自然图像可以分解为描述平稳变化结构的低空间频率分量和描述快速变化的精细细节的高空间频率分量。类似地,我们认为卷积层的输出特征映射也可以分解为不同空间频率的特征,并提出了一种新的多频特征表示方法,将高频和低频特征映射存储到不同的组中,如图 2(b) 所示。因此,通过相邻位置间的信息共享,可以安全地降低低频组的空间分辨率,减少空间冗余,如图 2(c) 所示。
How?—再探OctConv
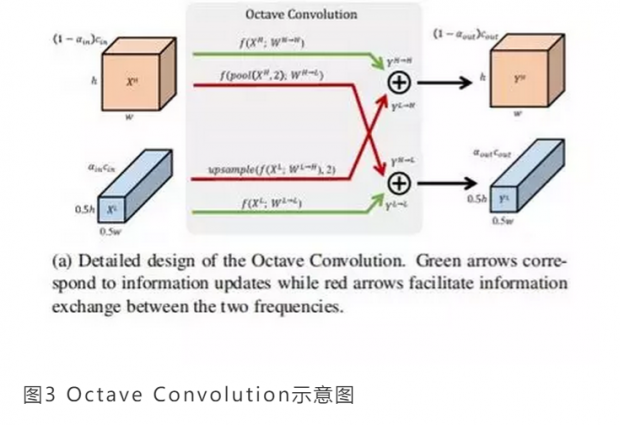
论文Method(方法)部分:octave feature 减少了空间冗余,比原始表示更加紧凑。然而,由于输入特征的空间分辨率不同,传统卷积不能直接对这种表示进行操作。避免这个问题的一种简单方法是将低频部分上采样到原始的空间分辨率,将它与连接起来,然后进行卷积,这将导致额外的计算和内存开销。为了充分利用紧凑的多频特征表示,我们提出 Octave Convolution,它可以直接在分解张量X={XH,XL}上运行,而不需要任何额外的计算或内存开销。
Octave Convolution的设计目标是有效地处理相应张量中的低频和高频分量,同时使得Octave特征表示的高频分量和低频分量之间能够有效通信。设X,Y为分解输入和输出张量,那么输出的高频和低频信号将由下式给出:
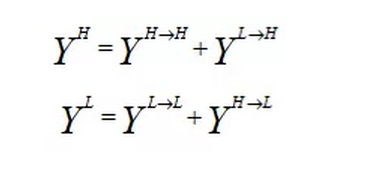
其中H→H,L→L表示自身的更新,L→H,H→L表示高频与低频分量之间的通信,如图3所示绿色箭头表示信息更新,红色箭头表示两个频率之间的信息交换。
同理,我们将卷积核分解为高频和低频W={WH,WL},WH=WH→H+WL→H;WL=WL→L+WH→L,如图4所示:
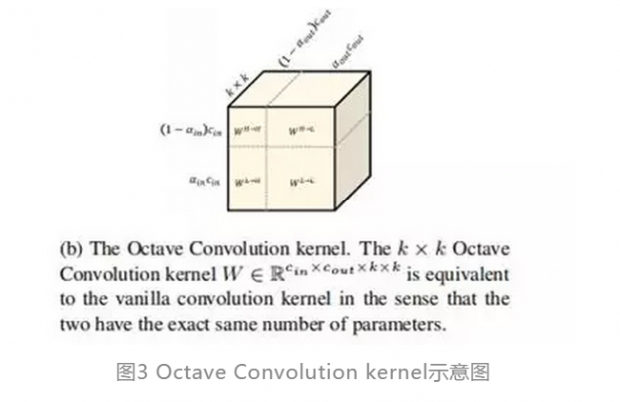
对于低频特征所使用的低频所占比例a的不同,当a=0时(即没有低频成分),OctConv就会退化为普通卷积。经过实验评估k×k Octave 卷积核与普通卷积核等价,即二者具有完全相同的参数量。
To do—Just do it
论文的实验部分:研究人员验证了提出的Octave卷积对于2D和3D网络的效能和效率,首先展示了ImageNet图像分类的控制变量研究,然后将其与当前最优的方法进行了比较。之后研究人员使用Kinetics-400和Kinetics-600数据集,展示了提出的OctConv也适用于3D CNN。
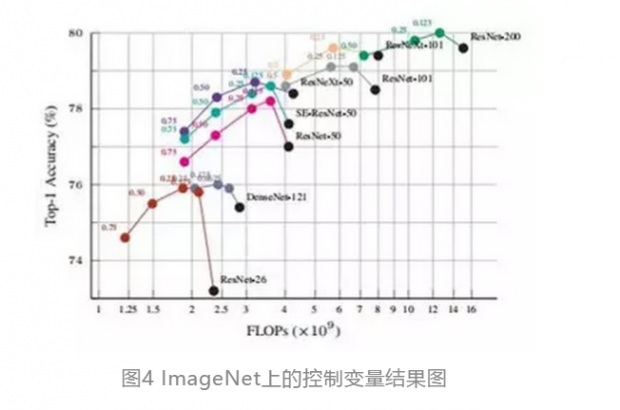
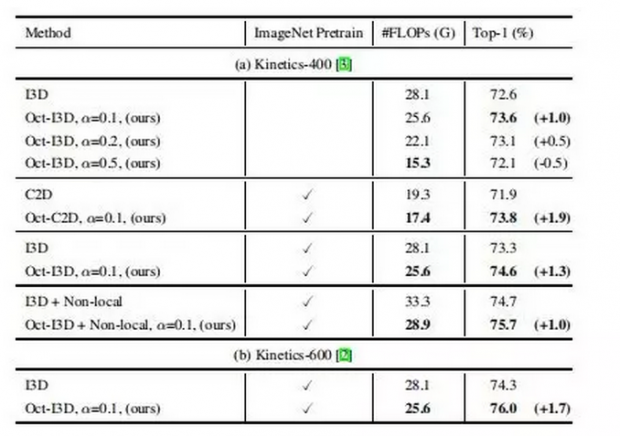
上表为论文中的表8,视频中的动作识别、控制变量研究结果统计。
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号