阅读:0
听报道
作者:Christopher Dossman
编译:Joey、Junefish、云舟
本周关键词:推荐系统、AlphaZero、人脸识别
本周最佳学术研究
Bot检测利器ZKSENSE,保护你的移动设备
研究人员最近推出了ZKSENSE,这是一种基于传感器和情境感知的bot检测系统,它可以检测在移动设备上执行操作的人类性,并且不会给用户体验带来负面影响。ZKSENSE使用的是ML模型,通过研究特定动作过程中移动设备运动传感器的输出,来检测动作是由机器人发起的还是人类发起的。
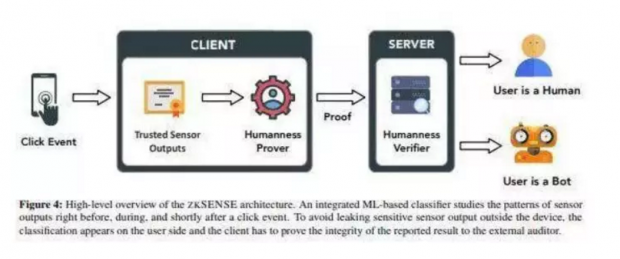
为了训练这个模型,研究人员使用了公开的传感器数据和从一小批志愿者那里收集的数据。经过评估,ZKSENSE在各种机器人场景中均显示出91%的准确性,而且这实在不影响用户体验或者威胁用户隐私的情况下达成的。
随着现代计算系统的日益数字化以及人们向移动设备的逐渐转移,对于服务提供商而言,他们亟需一种可靠的方法来验证客户端是否为人类,这将有助于防止用户端的自动化程序和机器人滥用其服务。
ZKSENSE对用户是完全透明的,并且不会向服务提供商透露任何敏感的传感器数据。与以前要求用户执行特定动作的方法不同,ZKSENSE完全无摩擦,不需要用户的任何额外介入。毫无疑问,它为目前的移动设备验证码方法提供了另一种可行的替代方案。
原文:
Google AI:针对推荐系统的可配置仿真平台
为了促进对推荐系统中RL算法的研究,Google AI开发了RecSim,这是一种用于编写仿真环境的可配置平台,支持与用户之间的的顺序交互,从而使研究人员和从业人员都可以在综合推荐环境中挑战和扩展现有的RL方法。
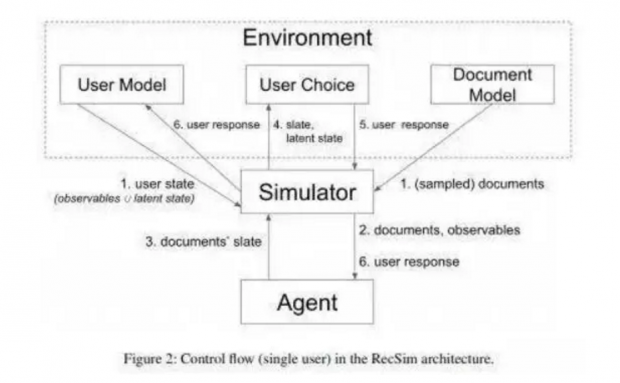
RecSim允许创建新的环境,该环境以一种抽象级别反映用户行为和项目结构的特定方面,非常适合在顺序交互式推荐问题中突破当前RL和RS技术的限制。使用者可以轻松配置各种环境,这些环境允许使用者改变以下假设:用户偏好和项目熟悉程度,用户潜在状态及其动态,选择的模型种类以及其他用户响应行为。
作为一个开源平台,RecSim为RL和RS领域的研究人员和从业人员提供了很多价值。它可以通过促进研究界的模型共享和可重复性,充当学术与工业合作的工具,从而增加研究人员在不同强化学习和推荐系统的参与度。
对于有兴趣应用RL的RS从业人员,RecSim可以在程式化推荐器设置中挑战标准RL算法中做出的任何假设,识别这些假设的陷阱,以使从业者可以专注于RL算法中所需的其他抽取。因此,这将减少实验周期,加速开发并完善仿真模型,并最大程度地减少对实际系统中的用户产生负面影响的可能性
原文:
达到AlphaZero超人性能的新方法
MuZero是一种基于模型的增强学习新方法,它无需任何关于其基本动态的知识,即可在一系列充满挑战的复杂视觉领域中实现最先进的性能。
MuZero建立在AlphaZero强大的搜索功能和基于搜索的策略迭代算法上,并将学习到的模型整合到了训练过程中。当它学习了一个模型并将该模型应用于迭代时,可以预测与计划最直接相关的特征数量,包括奖励,行动选择策略和价值函数等。
对57种不同的Atari游戏的评估结果表明,MuZero达到了新的技术水平。在对围棋,国际象棋和将棋的评估中,MuZero在不了解游戏规则的情况下达到了AlphaZero算法的超人性能。
MuZero结合了高性能计划和无模型强化学习方法的优点,这些方法过去曾推动了机器学习的众多突破。
该算法在其擅长的领域,即视觉复杂的Atari游戏中,优于最新的无模型增强学习算法。最重要的是,MuZero不需要任何游戏规则或环境动态知识,面对存在许多不完美画面模拟器的现实世界,这有可能为强大的学习和计划方法的应用铺平了道路。
原文:
历史上第一个完整的人类头部3D表示方式
在本文中,研究人员们提出了有史以来第一个完整的人体头部3D变形模型(3DMM)表示。这一模型从一定意义上来说是完整的,因为它可以验证人类头部所有主要可见表面(包括脸部、颅骨、耳朵和眼睛)的有意义变化。
研究人员对现有的两种对头部建模的方法进行了整合。首先,他们使用回归模型来弥补其中一个模型的缺失部分。在此之上,他们使用“高斯过程”框架来混合来自多个模型的协方差矩阵。因此,他们建立了一个新的组合的面部和头部形状模型,将现有面部模型(LSFM)的变异性和面部细节与现有头部模型(LYHM)的完整头部建模能力融合在了一起。

然后,他们构建并融合了细节度很高的耳部模型,以扩展耳朵形状的变化。他们还把眼睛和眼睛区域模型以及牙齿、舌头和口腔内部模型的都一同合并到了头部模型中。
这一最新模型达到了有史以来最先进的建模性能。研究表明,这一方法产生的统计模型明显优于原始的构成模型。
本文提出的这个方法能够通用于很多不同情境,它可以将来自对象类不同部分的3DMM组合到单个3DMM中。研究人员能够创建大规模的头部可变形模型,该模型具有比以前任何其他建模方式更完整的形状表示。
同时,值得注意的是:研究人员并没有处理头发,也无法完全模拟口腔内包括牙齿和舌头在内的统计形状变化,这对于实现逼真的语音动态至关重要。他们仅对外部颅面形状进行了统计学建模。他们的技术很容易扩展以结合人体的模型,并且确实适用于3DMM很好描述的任何物体或对象。
原文:
视频中的实时人脸识别
Facebook AI Research提出了一种用于人脸识别的新方法,该方法可实现高帧率的全自动视频修改。他们的这一方法是目前唯一适用于视频(包括实时视频)的人脸识别方法,其质量远远超过了其他方法。
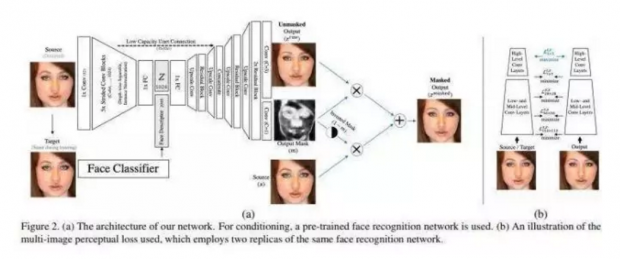
这一方法的目标是:在姿势、照明和表情等能够感知的量固定的前提下,最大程度地消除识别结果和身份的相关性。研究人员通过一种新的前馈编码器/解码器网络体系结构实现了这一目标,而这种体系结构的特点是它以人脸图像的高级表现为条件。这一网络的适用性很高,无需为给定的视频或给定的身份进行单独训练。它还可以创建时间序列几乎没有失真的自然图像序列。
随着人脸识别技术的大量进步以及该领域滥用案例的增多,成功处理身份识别的方法越来越重要。
他们提出的方法允许创建相貌相似的人的视频,从而从一定程度上“改变身份”。这使用户有可能以匿名方式在公共论坛中留下看上去自然的视频消息,这很可能会阻止面部识别技术对其进行识别。
原文:
其他爆款论文
研究人员发现,在模型训练过程中使用未标记的数据可大大提高图像分类的准确性:
使用TensorFlow来增进对基础物理学的理解:
使用反向传播学习更快的扩增策略:
对当前用于面部识别系统的深度学习技术的系统性研究:
如何应用简单的2D“序列到序列”模型作为基于注意力模型的替代方法:
数据集
一个按照主题归类的公开数据集:
AI大事件
MIT开发AI系统为驾驶行为评分:
AI将使超级计算机的速度提高十亿甚至一万亿倍:
想知道哪些公司在使用AI跑赢市场:

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}