阅读:0
听报道
作者:Christopher Dossman
编译:Vicky、Olivia、云舟
本周关键词:视觉跟踪、GANs、知识转移
本周最佳学术研究
大规模任务中SpecAugment的有效性研究
近来,SpecAugment(一种用于自动语音识别的增强技术)已经能够高效地增强公共数据集上端到端网络的性能。而对于大规模任务,它是否依旧高效呢?
本文研究了SpecAugment,并展示了它在Google Multidomain Dataset(一个大规模多领域数据集)上的有效性,该数据集包含来自不同领域的多个测试集。在训练声学模型时,研究人员混合使用了SpecAugment增强的原始训练数据和受噪声干扰的训练数据,从而在所有测试领域中取得了进步。他们还优化了SpecAugment使其根据发声的长度来调整时间掩码的大小及多重性,这可能对完成大规模任务有帮助。
通过应用自适应掩蔽,LibriSpeech上的“侦听”、“参加”和“拼写”模型的性能均有所提高。在测试清洗时,WER可达到2%以上;其他测试时,WER可达到5%以上。
研究发现, SpecAugment虽然简单,在大型数据集上,却能取得比传统的和更复杂的增强方法更好的结果。而且计算优势让它可以被整合到工业规模任务的数据管道中,这一点使它更具潜力。
研究人员还为SpecAugment引入了自适应时间掩蔽。尽管他们没能在Google Multidomain Dataset上找到一个优于非自适应策略的自适应策略,但他们展示了LibriSpeech 960h上自适应掩蔽的有效性。他们期望进一步探索自适应掩蔽,来提高大规模任务中SpecAugment的表现。
原文:
暹罗运动感知网络:实现更准确和高效的视觉跟踪
来自中国和美国的一组研究人员提出了一种用于视觉跟踪的最新暹罗运动感知网络(SiamMan)。SiamMan使用Pytorch实现,并由暹罗特征提取子网和三个并行分支组成,这三个分支分别为分类、回归和本地化。
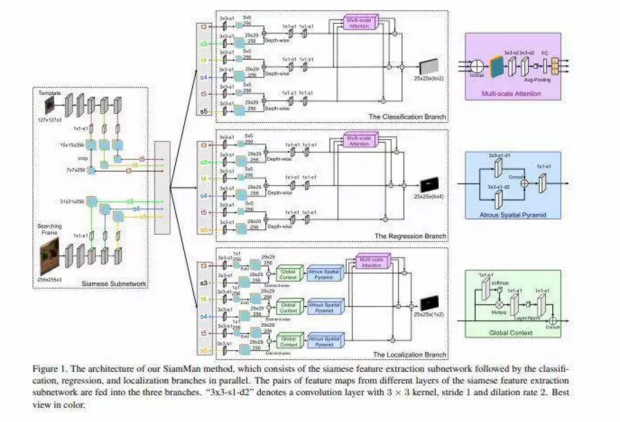
为了捕获远程的依赖关系,研究人员将全局上下文模块集成到了本地化分支中,从而使跟踪器处理大目标位移时的效果更加稳定。他们还设计了一个多尺度、可学习的注意力模块,以指导网络利用多个判别特征获得准确的结果。
SiamMan在四个具有挑战性的基准(包括VOT2016,VOT2018,OTB2015和LTB35)上都取得了最优秀的结果,其性能与UAV123上最先进的设备相当。
SiamMan显著减少了跟踪失败的次数,因此可以高效地达到优秀的精度。它可以定位目标,从而帮助回归分支产生更准确的结果。在快速运动、遮挡和低分辨率等挑战发生时,SiamMan的表现也更好。研究人员还设计了一个多尺度的注意力组件,用来指导三个分支利用判别特征达到更好的性能。
代码:
原文:
MineGAN:从GAN到少量图像的目标域进行有效知识转移
MineGAN是一个将知识从多个GAN转移到单个生成模型的方法。使用矿工网络可以生成看起来非常类似于目标域的图像,从而实现挖掘GAN的过程。本文所提出的网络具有比预训练的GAN少得多的参数,因此更不容易产生过拟合。

在无条件、有条件和多个GAN传递知识等设定下测试该方法,并在高复杂性的高分辨率数据集(如LSUN,CelebA和ImageNet)上对其进行评估。结果发现,MineGAN比包括TransferGAN和BSA在内的传统网络表现更好。
MineGAN允许同时汇总多个来源的信息,从而能够生成与目标域类似的样本。这使得知识能够从多个预训练的GAN转移,因此该方法可以用于单个或多个预训练的GAN。
在多个数据集上对包括Progressive GAN、BigGAN和SNGAN在内的各种GAN体系结构进行的实验,证明了该方法的有效性。这项工作还表明,我们可以通过选择性反向传播技术来训练网络。
原文:
开发有效的医疗保健机器学习模型
谷歌的科学家们与谷歌健康团队最近合作发表了两篇论文,旨在改进针对医疗保健方面的机器学习研究。
第一篇名为《如何为医疗保健开发机器学习模型》的文章,旨在帮助机器学习从业者更好地理解如何为医疗保健开发机器学习的解决方案;第二篇文章名为《医学文献用户指南:如何阅读使用机器学习的文章》,适用于那些希望更好理解机器学习并使用机器学习改善临床工作的医生。具体而言,本文旨在揭开机器学习的神秘面纱,以帮助需要使用机器学习系统的医生了解其基本功能、有效性以及它们潜在的局限性。
我们生活在一个令人兴奋的时代,一个能在众多领域体验人工智能进步的时代。医疗保健中的人工智能涉及范围很广,它要求机器学习进行大规模的开发、测试和实施。它还需要来自不同学科的研究人员和专家之间进行有效合作。
现在,这些论文促进了各领域之间迫切需要的合作,一方面它们帮助机器学习从业者了解了开发医疗健康模型时的注意事项,另一方面则为医生评估和使用机器学习模型提供了指导,这些举措最终都对患者的治疗和护理产生了积极影响。
原文:
公平性指标:公平机器学习系统的可扩展基础架构
在TensorFlow World大会上,Google AI发布了beta版本的公平性指标,这是一套可以对二进制和多类分类的公平性指标进行定期计算和可视化的工具套件,这一系统可以帮助团队朝着识别机器学习中不公正的影响迈出第一步。
这项工作涵盖了很多内容,包括什么是机器学习公平性、公平性指标工具套件、如何在当今模型中使用公平性指标、公平性指标案例研究、入门视频以及进一步的研究探索等等。
公平性指标可用于生成透明度报告的指标,其中一个例子是用于模型卡的指标,它可以帮助开发人员在研究人员的指示下更负责任地部署模型。
但这些指标目前还有很大的局限性。因此,他们计划通过启用更受支持的指标(包括使人们能够在没有阈值的情况下评估分类器的指标)来进行垂直扩展,并通过创建利用方法的修正库来进行水平扩展。他们还希望在接下来的几个月里推出更多的功能和案例,从而真正奠定这项工作的基础。
GitHub链接:
原文:
其他爆款论文
实现鲁棒的神经网络分类:
基于图像识别的端到端模型,可用来预测自动驾驶汽车的转向角:
提高医学图像分析数据效率的新技术:
3D可控图像合成生成模型的无监督学习:
RoboCoDraw,一种基于机器人的实时合作绘图系统:
AI大事件
脸书、微软与亚马逊AWS诚挚邀请你参加deepfake检测大战:
航空公司关闭语音呼叫中心,认为客户体验的未来掌握在信息和基于声控的AI技术中:
数据科学菜鸟们的福音:数据科学开放职位增加超过50%:
猜猜什么是新加坡现在最需要的技能:
第33届最大的机器学习会议在温哥华开幕:

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}