阅读:0
听报道
作者:Christopher Dossman 编译:VICKY、Joey、云舟
本周最佳学术研究——KnowIT VQA:回答有关视频的知识性问题
在本文中,研究人员通过结合知识和视频问答,提出了一种新的视频理解任务。
首先,他们提出了一个称之为KnowIT(knowledge informated temporal)VQA的视频数据集。该数据集源自电视剧生活大爆炸(The Big Bang Theory),其中包含了众多知识问答。KnowIT拥有24000多个人工生成的问答对,并将视觉、文本和时间与基于知识的问题相结合。其次,他们提出了一个视频理解模型,将视频的视觉和文本内容与特定的节目知识结合起来。
他们发现:
知识的结合为视频中的VQA带来了显著改进;
KnowIT VQA的性能仍然落后于人类的准确性,这表明它对于研究当前视频建模的局限性是有所帮助的。

他们的工作表明了基于知识的模型在视频理解问题中的巨大潜力,这些模型将会为将自然语言处理(NLP)和图像理解的进步结合发挥重大作用。
该框架证明,视频理解和基于知识的推理都是回答问题所必需的。它能够检索并融合语言和视频的时空域,以便对问题进行推理,从而来预测正确答案。
但相比于人类的表现,(该框架)仍存在着很大差距。研究人员希望该数据集将有助于在该领域开发更鲁棒的模型。
原文:
https://arxiv.org/abs/1910.10706v3
用强化学习教机器人感知时间
众所周知,人类和动物的大脑具有负责时间认知的不同区域,而机器人则根据将时间视为外部实体(例如时钟)的算法来执行任务。是否有可能从生物学上激发时间感知机制,并在机器人中重现它们呢?
在这项工作中,研究人员观察了大脑用来负责时间感知的计时机制。他们利用贝叶斯推断得出的结果来预估数据的时间流逝,并利用TD学习特征表示来训练代理成功完成与时间相关的任务。由于选择了代表时间的特征,他们表明,在这种情况下,他们能够为代理提供一种类似人类和动物所经历的时间流失的感知。
本文的主要贡献:
提出了一种从机器人传感器收集环境数据的建模方法;
在特定假设下,可以从数据中获得正确的时间估算;
成功将时间认知机制应用于强化学习问题当中;
赋予机器人在与时间有关的任务中复制动物行为的能力。
这项工作提出了一种为代理提供时间认知的过程。对机器人来说,对于时间的感知能够让它们像人类一样,在不同的环境和人物中学习适应对话。该框架已被提议在未来在真正的机器人中实现。
原文:
https://arxiv.org/abs/1912.10113
Lite BERT:自监督学习语言表示
在本文中,Google AI的研究人员设计了一种Lite BERT(ALBERT)架构,该架构具有比传统BERT少得多的参数。一个类似于BERT-large的ALBERT配置与前者相比,参数减少了18倍,并且训练速度提高了约1.7倍。
ALBERT集成了两种参数归约技术:第一种技术是分解式嵌入参数化;第二种技术是跨层参数共享,它可以防止参数随着网络深度的增加而增长。这两种技术在不严重影响性能的前提下大大减少了BERT的参数数量,从而提高了参数效率。
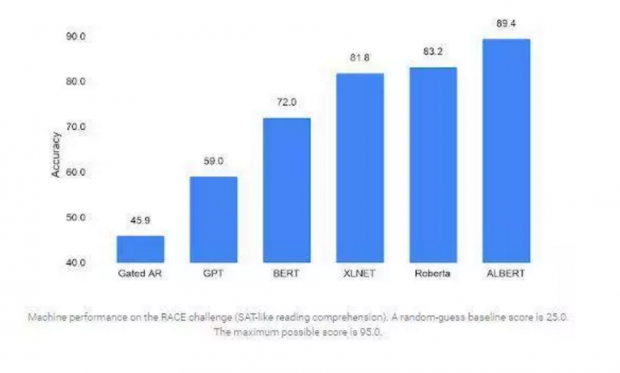
参数归约技术也可以作为正则化的一种形式,从而稳定训练并有助于泛化。
为了进一步提高ALBERT的性能,研究人员还引入了一种自监督的损失来进行句子顺序预测。结果,他们能够扩展到更大的ALBERT配置,同时这些配置的参数仍然比BERT-large少,但性能却明显提高,从而在GLUE、SQuAD和RACE基准上为自然语言理解建立了全新的结果。
ALBERT的成功证明了它在识别模型方面的重要性,因为它在这些方面产生了强大且适当的表示。
通过集中精力改进模型体系结构的这些方面,这项研究表明了可以在广泛的NLP任务上极大提高模型的效率与性能。为了促进NLP领域的进一步发展,研究人员已将ALBERT开源给研究界。
代码与预训练模型:
https://github.com/google-research/google-research/tree/master/albert
原文:
https://ai.googleblog.com/2019/12/albert-lite-bert-for-self-supervised.html
有序还是无序?让我们重新审视用于视频的人物身份识别
基于视频的人员身份“再识别”方法是近些年来计算机视觉领域中一个热门研究方向,因为它可以通过充分利用时空信息来达到更好的识别结果。
在本文中,研究人员提出了一种简单但十分惊艳的VPRe-id方法,他们将VPRe-id视为基于图像的人员重新识别问题的有效无序集合。

具体来说,研究人员们将一段视频划分为许多个单独的图像,然后对这些图像中出现的人进行识别和排序、并重新组合出最终结果。他们以i.i.d.假设为前提,提供了一个错误边界用于阐明改进VPRe-id的方式。
这项工作还提出了一种很有前景的方,可以弥合视频和人物信息重新识别结果之间的差距。研究人员们对这个差距进行评估,证明了他们所提出的这一方案在多个数据集(包括iLIDS-VID、PRID 2011、和MARS)中都达到了业界领先的水平。
基于视频的人物重新识别非常重要,因为它在视觉监视和取证等领域有着广泛应用。这项工作通过将VPReid视为一个进行无序整体排名的任务,提出了一种简单而强大的人物重新识别的解决方案。其中,每个基本排名都由一个具有单个人员身份的标识符来体现。
该解决方案通过使用RNN输出在不同时间步长上的时间池中的多个特征表示,学习了无序表示,研究人员认为这对于VPRe-id更为重要。结果也证明了我们可以从不同角度解决VPRe-id这一事实。
原文:
https://arxiv.org/abs/1912.11236v1
一个使用Python可视化工具实现的全新文本分类器
近日,一个名为SS3的文本分类机器学习模型横空出世,它非常适合处理社交媒体信息流上的ERD问题。在CLEF eRisk开放任务(例如侦测早期抑郁、厌食和自我伤害)上达到了业界领先的水准。
在本文中,研究人员介绍了PySS3:这不仅是一个实现了SS3的Python框架,而且还附带可视化工具,使研究人员可以部署更强、更加容易解释且值得信赖的机器学习模型来进行文本分类。
PySS3是一个开放源代码的Python框架,它实现了SS3,并带有两个有用的工具,这些工具让开发者能够以非常简单、易交互和可视的方式使用它。例如,其中一个工具能使用可视化工具对模型进行解释,该可视化工具直接突出显示原始输入文档的相关部分,从而使研究人员能够了解所部署的模型。
PySS3是使用Python开发的,并经过专门编码来与Python 2.7和Python 3.x兼容。 此外,它还与不同的操作系统兼容,例如Linux、macOS和Microsoft Windows。
PySS3带有针对研究社区的实用开发与可视化工具,它为研究人员和从业人员提供了一个平台,可以部署强有力的、可解释的和可信赖的机器学习模型进行文本分类。
它还允许他们部署SS3模型并通过特殊命令在机器学习的每个阶段(包括模型选择、训练、测试等)与它们进行交互。
原文:
https://arxiv.org/abs/1912.09322v1
其他爆款论文
研究人员提出了这些问题期望能够指导人工智能研究的未来:
https://arxiv.org/abs/1912.10305
深入分析不同的特征处理和建模方法以及情感识别结果:
https://arxiv.org/abs/1912.10458
如何提高现有多对象跟踪器的性能——深度多对象跟踪器的端到端训练:
https://arxiv.org/abs/1906.06618v2
研究人员开发了一种非常轻量级而快速的表情识别模型 —— MicroExpNet,用于正面图像的面部表情识别(FER):
https://arxiv.org/abs/1711.07011v4
区分CNN生成的图像与真实图像区有多困难? 事实是:CNN生成的图像非常容易发现,起码暂时是这样的:
https://arxiv.org/abs/1912.11035v1
AI大事件
人工智能在2020年将如何发展? 2020年有趣的AI预测:16位专家发表看法
https://www.verdict.co.uk/2020-artificial-intelligence-predictions/
Facebook正在开发自己的操作系统!
https://www.theverge.com/2019/12/19/21030043/facebook-os-custom-operating-system-android-reliance-self-sufficiency-ar-glasses
随着AI芯片市场的蓬勃发展,英伟达的领导层面临挑战:
https://www.investors.com/news/technology/ai-chips-nvidia-artificial-intelligence-stocks/

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号